汉化基础教程完整版
—— PGCG汉化组
http://pgcg.gbgba.com/
http://www.tgbus.com/gba/pgcg/teach.htm
一 心态篇
游戏汉化是一个费力又费时的工程,没有游戏厂商的开发源程序,没有固定的某个软件,也没有固定的方式,一切都得靠自己手工劳作。汉化游戏对个人的态度与心理素质要求都比较高,所以在开始学习汉化前有必要先上一堂心态课,用意在于让大家对汉化游戏有个思想上的认识,有个心理准备。
汉化不是三言两语就能说清楚道明白的,也不是喝口水、眨下眼就能精通的!!!。各位初次接触的新人想必都怀着不同的理由才投身汉化的,但无论是什么最终目的都是想把一个个日文游戏变成通俗易懂的中文游戏。在这个共同点上是十分值得赞扬的,不过我也想提醒大家,希望大家对汉化有个正确的认识。汉化者必须具备的3个条件:1、坚持不懈、持之以恒的耐力。2、熟练的计算机操作能力。3、广泛的计算机知识。其中最为关键的就是耐心毅力,在汉化中必定会遇到现实与潜在的双重困难,任何一个困难都有可能使你放弃汉化,面对种种错综复杂的困难,良好的心态显得十分重要。困难不是不能克服,而是看你愿不愿意去克服。汉化不仅是游戏的汉化过程,同时也是自身能力提高的过程。而在这之中伴随的来自于自身(生活、学习等)和外界(Lamer)的压力同样可能使你屈服,这同样也得靠耐心来趋势自己继续前进。“勤能补拙”,良好的耐心毅力能弥补自己在其他方面的不足,而重点是“勤”。它可以使自己的能力得到飞速提高。从事汉化研究的人群多为青年,青年具有先天的求知欲与积极向上的精神,但是另一方面,中国青年浮躁、不踏实、意气用事的心理却往往会制约自身的能力提高。要想在汉化方面真有所建树首先就必须端正自己的思想,净化自己的心态。
汉化对于计算机知识要求是广而不精,所以这给当代年轻人创造了极为便利的条件。即便是现在才开始学习,学起来也不费劲。说到学这个问题还得说一说。由于汉化的特殊性质在目前的社会看来并不能算作一个正规的行业,因此即便是电脑技术书籍泛滥的今天想要找到一本专门讲解游戏汉化理论原理的书实在是极为不容易,所以所有关于这方面的学习都利用网络来进行学习与交流。网络上有不少爱好游戏汉化的热心人,他们不但自己汉化游戏,也常常把自己学习的经验技术带给大家,传授给大家。“狼组”、“天使汉化小组”的网站上都有很详细的汉化知识讲解。目前大部分汉化人都是从那里起步的。如果你还是新人一定要去看,把那里旮旯里的东西都学到,都消化为自己东西。学习阶段不能只顾看,实践才是目的。大部分教程都是伴随一个例题游戏进行的汉化讲解与演示的,所以建议在学习的时候旁边最好是准备好这些个游戏素材,边学边做。当然,教程所教授的内容是十分简单的,又是十分片面的。而在亲自操刀的汉化过程中将会遇到很多无法预料的问题,需要大家克服浮躁的心理善于思考勤于思考。在真正掌握一些基础知识并具备一定能力后不能轻易自满。学到的这些还只是个开头,接下来还有更多更严峻的问题。这仍然需要持之以恒的学习态度。此外经验交流也是必不可少的,志同道合的几个人可以经常在一起讨论切磋,以达到共同进步的目的。自己不懂的要向别人请教,请教不是叫你去问这步该如何如何,下一步又该如何如何等等这样的操作性问题。应该问的是原理,即为什么需要这样?请教也不能产生依赖,绝不能一遇到问题就去问,问个没完没了。合理的是得知某一问题的原因以后首先要自行分析,认清问题的真正原因后去立刻解决问题,解决完后再进行横向纵向的拓展,即找到此问题的一般性与特殊性,哪些情况会出现这样的问题,对于出现的问题各自采取什么办法等等。再有,网上的汉化资料讲解的方法技巧都是最典型最普遍的流程,汉化没有固定的路径。游戏结构的多种多样,导致实现汉化的方式方法也可以多种多样,不要生硬地照搬硬套,要多思考,灵活运用;具体问题具体分析,不同的情况用不同的方法处理。在实践的过程中要善于积累适合自己的经验技术。同时,当遇到实际情况与教程不大相同或者相抵触的时候要能够举一反三。
另外,在自身汉化经验上升到一定程度后熟练掌握一门计算机编程语言是十分必要的事情,汇编基础必不可少,很多时候都必须通过分析游戏指令来汉化游戏,而且这十分普遍,不懂的此技能的汉化者几乎不可能独立完成一个游戏的破解工作。高级程序语言,例如Basic C/C++,要学会利用这些高级语言来编写小程序以达到事半功倍的效果,同时也是自身能力又一次提高的过程。关于语言的学习就大家自己去摸索吧。还要强调的是:汉化需要堆积大量的时间与精力,极不赞成高中学生来做这方面的研究,学生当以自身学业为重。
汉化需要热情与激情,但更需要耐心与毅力,当你心中真正装有汉化的时候它就不再那么神秘得高不可攀了。
小结:如果你能耐心地看完这篇枯燥得只有白底黑字的不涉及任何技术性的文章后仍然对汉化充满充满无限热情,那你就具备了汉化所必须的也是最基本的条件。以后的学习研究过程中一定要深思考、勤探索。汉化没有捷径可图,靠得是脚踏实地坚持不懈地再攀登。搞任何研究都不能有依赖性,汉化也不例外,绝不能像玩网络游戏那样寄希望于高手来带你,或者期待某个高手编写一套“外挂”来助你成功。汉化主要是靠自己的研究,我们学习的不仅仅是操作,而主要的应该是原理。因为汉化不像使用WORD编辑文书那样,学会了操作在哪台电脑上都是一样的进行。游戏是千变万化的,没有任何两款游戏的汉化操作是完全一样的。我们要掌握游戏运行的原理,汉化的原理,从而才能举一反三灵活运用。汉化新手一定要注意自己的心态问题,只有建立正确的汉化观才有可能真正学会汉化。从下次开始我们将逐步展开汉化的学习,希望对汉化有热情的玩家学有所获。
二 基础篇(上)
上期我们谈了关于汉化的心态问题,别看他并没有什么技术含量,但他却决定了学习实践的成功与否。从这期开始,逐渐讲解汉化的理论知识。汉化不外乎就是把游戏里面的异国文字修改成咱们中国人所使用的中文汉字,请记住是中文汉字,而不是日文中的汉字。所以我们的研究对象就是游戏中的文字。下面我们就从文字开始研究:
首先,我们先别慌着开始汉化研究,因为汉化涉及许多电脑方面的基础知识,我们必须先来学习一下这戏基础。如果你对自己的电脑知识掌握程度有相当的把握那就跳过这一部分继续往下看,如果没有就一定要认真地看。
二进制(0 1):不管是电子计算机还是游戏机在存储数据的时候都是以二进制的方式进行储存的。因为电子电路能表示的就只有两种状态,要么通电要么断电(电子电路是与非门电路,准确来讲应该是高电位和低电位两种状态,这里为了简单化就认为成通电与断电)。而我们人类只习惯于十进制,所以要读懂二进制就先转化为十进制。又由于二进制的一位表示的数值太小,如果要表示一个比较大的数字的话这个二进制数字就相当的长,这样不便于人们辨识。所以从二进制里面派生出了八进制(0 1 2 3 4 5 6 7)和十六进制(0 1 2 3 4 5 6 7 8 9 A B C D E F),每三位二进制数可以转换为一位八进制,每四位二进制可以转换为一位十六进制。怎样互换这些不同的进制数值是个数学问题,高中文化都知道的方法,如果实在不懂的话可以使用任何一款科学计算器,Windows系统里面就带有。123D表示十进制,123H表示十六进制,末尾的D H这些字母标明数值的类型。
位bit与字节byte:我们常说的电脑是32位;PS是32位;GBA是32位,这里的32位指的是核心CPU寄存器的宽度,1位就是1个二进制位的宽度,32位就是32个二进制位的宽度,也是8位十六进制宽度,数值表示范围从00000000H-FFFFFFFFH。两位十六进制数为一个字节byte,数值范围00H-FFH;两个字节为一个字;两个字为一个双字。由此可得几个单位的转换关系:1GB(byte)=1024MB 1MB=1024B 1B(byte)=8b(bit)。MB和Mb是两个单位,任天堂的卡带容量都是以Mb为单位的。
文件与存储:电子设备在保存记录信息的时候也是二进制的方式来保存的,文件也是一样,无论是rm mp3还是txt 甚至游戏ROM也是这样的。但有一点需要注意:在保存数值信息得时候,数值是以字节为单位,高地址存放高位字节,低地址存放低位字节。什么意思呢?举个例子:1234H 这个数有两个字节的宽度,在保存的时候就应该是34 12,因为12是高位字节,34是低位字节,越往后靠地址越高。 我们再来认识一下文字在电脑中的存储显示问题。我们知道在电脑中储存的信息只有两种状态——0和1(二进制),所以我们就得把具体问题抽象为0和1的问题。一般来讲,文字在电脑中保存有两种形式:文本形式和图片形式。 先来研究文本形式的文字。最基本的就是把字符点阵化然后把每个点的状态转化成二进制代码。以字母“A”为例:
○ ○ ○ ○ ○ ○ ○ ○
○ ○ ○ ● ● ○ ○ ○
○ ○ ● ○ ○ ● ○ ○
○ ● ○ ○ ○ ○ ● ○
○ ● ○ ○ ○ ○ ● ○
○ ● ● ● ● ● ● ○
○ ● ○ ○ ○ ○ ● ○
○ ○ ○ ○ ○ ○ ○ ○
这是8*8像素字母A的点阵构成 我们把每个点的状态转换成二进制数值,用0表示○;1表示●,按照这个规则从左到右从上到下排列就可以得到:00000000 00011000 00100100 01000010 01000010 01111110 01000010 00000000。
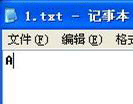
转换为十六进制:00 18 24 42 42 7E 42 00,这就是最简单的表示方法,但这并不是字母“A”在文件中的保存形式。我们可以使用“记事本”(一定要使用记事本)创建一个纯文本文件,里面输入唯一的一个大写字母A,然后我们再用任何一个十六进制编辑器打开这个保存的文件就会发现问题(推荐UltraEdit):文件中只有唯一的一个十六进制值——41H。为什么不是我们得到的00 18 24 42 42 7E 42 00?道理很简单,如果文字都按照这样的方式储存并表示的话那文件就太大了。计算机在保存文本的时候并不是直接把文字的点阵信息记录到文件中,而是把点阵记录到系统字库里,而文件中就记录下这个字符的代码值。在读取的时候先把代码值41H读取出来,再通过字符映射找到41所对应字符在系统字库里面的实际位置,接着再把这个位置的信息00 18 24 42 42 7E 42 00读取出来通过显示程序显示在屏幕上的。字符映射表就是详细记录代码与字符点阵的对应关系,为一一映射,没有一对多也没有多对一。调用系统字库可以大大节省文件的容量,提高显示效率。映射表在汉化的时候也可称为码表。在电脑中最典型的内码就是ASCII,“41”(十六进制)就是英文字母“A”的ASCII码值。ASCII里面包含了所有英文字符和标点符号的映射关系,ASCII编码的时候为单字节,所以A只占用一个字节。汉字的内码比较多,主要有GB2312(简体)和GBK(繁体),汉字编码一般为2个字节,所以表示一个汉字所占用的空间就是英文字母的两倍。这一原理相当的重要,日后汉化中都是围绕这个过程展开的。其实从这个原理就可看出为什么汉化英文游戏比日文游戏难度大的原因。
再来说说图片形式的文字。顾名思义,图片文字就是把文字保存为图片。图片形式的文字字样:

像这样的文字就是图片文字,文字本身就是一种图形,计算机在存储的时候要比文本型文字的原理要简单,仅仅是把每个象素转换为二进制以后按照图片规定的格式保存下来。转换后的数据本身就是图片信息,不像文本那样有对照表。使用这种图片文字的好处就是可以使文字显得更加美观更加个性化、艺术化,还可以和其他图片相结合在一起。计算机或者游戏机在读取信息后就可以直接显示,不用再依照内码表进行数模(字模)转换。所不足的就是这种文字占用的空加要比文本文字暂用的空大许多,所以就不能反复使用这种形式的文字。一般来说,在游戏中图片文字用来作为游戏进入界面,游戏标题,控制界面等等少量的或需要美化的地方,比如“黄金太阳”、“ShiningSoul”、“SEGA”、“KONAMI”、“HP”、“MP”这些字符大都使用图片格式。游戏里面的对话,剧情介绍,道具名称,道具介绍,状态描述等等,则大都采用文本文字,因为这些文字量比较大而且会重复出现,因而就必须从容量上考虑,再说这些地方对文字要求是正规、统一、协调,以便于阅读。总的来说,图片文字原理比较简单,但占用空间大;文本文字原理比较复杂,好处是占用空间小。
小结:游戏机在本质上和电脑没有太大区别,所不同的就是用途。汉化的前提是对电脑基础知识的掌握,考验的是汉化者的综合素质。对游戏的汉化就是对文字的修改,所有的游戏文字都离不开以上两种方式进行存储和显示的,我们必须深刻理解其中的原理。
三 基础篇(下)
上一节我们主要研究了一下文本文字的原理,今天我们在来看看图片文字。图片文字实质上就是图形,这种文字在存储规则上与普通图片是完全一致的。我们先来了解一下图片的构成要素:
像素:构成图片点阵的点单元数目。因为图片都是矩形的,所以我们可以用“宽”和“高”两个参数来描述,即分辨率。比如上一期中谈到的那个字母“A”的点阵图就是一个宽8像素高8像素的一个图片,分辨率就是8*8。像素是以点单元也就是像素点为基本单位的,并非厘米毫米。至于点的大小则是由硬件本身的性质决定的。GBA屏幕的分辨率为240*160。
色深:构成图片调色板的颜色数量。色深一般有单色、4色、16色、256色、16位色、32位色等等,色深越大图片颜色越丰富效果也就越好。图片的调色板固定了,图片所用到的颜色范围也就固定了,图片所用到的颜色都是从调色板里取出来的,调色板没有的颜色就无法取到,图片里也就不可能出现这种颜色。图片的色深决定了图片存储时每个像素所占用的空间长度。
色素:像素点的颜色。表示颜色有很多方法,用得最多的就是RGB(Red,Green,Blue)三元色,所有的颜色都可以通过红绿蓝这三色的深度表示出来。(255,255,255)就是一组RGB值,它表示黑色,(0,0,0)表示的是白色,随着这三个值在0-255的范围内变化,颜色也会随之变化。
图片要素还有很多,这里不作专业讨论,我们只谈了与修改有关的要素。图片要得到保存,最起码也得记录下图片的这两个属性——调色板、色素。就我们上次的字母“A”点阵图来说,可以把它看成一个只有白色和黑色两种颜色的图片。我们先来做个实验,看看图片究竟是怎么保存的。首先,我们打开Windows的画图工具,在里面把画布的大小调整为8*8,然后随便用一种颜色填充整个画布并保存为16色位图bmp格式(图1),保存的时候不用担心颜色发生的变化。
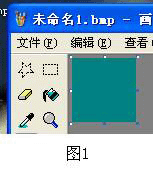
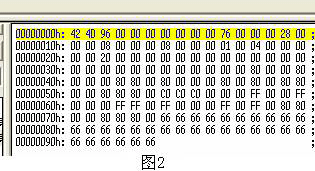
因为画板的默认调色板为24位色,我们保存为16色调色板必然会丢掉大量的颜色,如果碰巧我们使用的这种颜色恰好被丢掉的话系统会自动采用16色调色板里面最近似的颜色加以保存。不过我们研究的不是颜色的丢失。接下来用十六进制编辑器打开这个图片,我们将会看到图2的内容。如果大家填充的颜色与我得不一样的话立刻就能找到不同的地方。不错,文件最后的三排的内容完全不同,你的可能是0-F的任何一种,反正我的就是一串6。聪明人立刻就会明白这其中的奥秘了吧,猜得没错就是那样,文件最后的这些信息就是画布每个点的颜色。

我们可以来修改修改,看看是不是这样,从76H到95H(这里指的是地址,窗口状态栏有标明光标所在点的地址值)所有的内容都改为0,然后再用画图程序打开看看(图3),我们的画布全都变黑了。确实如此,bmp格式的文件就是把每个点的颜色索引值逐个逐个地记录下来的。既然文件末尾的那些值才是点的颜色,那前面的数值又有什么意义呢?读者可以按照这个方法继续进行对比分析,意义都很简单,为了节省篇幅,这里就略去了。在bmp格式中文件结构可以分为三部分,最开始的两三排内容为文件头,记录着文件的像素、色深等基本信息,紧接着的是调色板每个颜色的RGB值,每一组占用3个字节,地址从低到高依次为Blue Green Red(符合上一讲数值存储的基本规则),一共有16组(因为我们保存的是16色格式)接着调色板的就是每个点的色素索引值,也就是我们看到的那一串6。需要说明一点,我们所做的图形研究必须是bmp格式,之所以要研究这种格式,一是因为他简单,便于研究,是一种非压缩图形格式(其他的诸如jpg gif png这些都或多或少有压缩的,存储规则都比较复杂),因而bmp格式的文件随着图片的扩大,色深的增加文件容量也会随之剧增。二是由于游戏ROM里面的图片保存原理也基本上和这种格式相同——调色板+索引值。
图片存储还有一些规则必须了解。色深不同保存后每个像素占用的空间就有区别,刚才我们所讲到的16色图片每个像素仅占用半个字节(因为只有16种颜色,所以就只有16个索引值用0-F表示出来),所以两个像素合起来才占用的是一个字节,合起来的数值在记录的时候是按位进行操作的,换句话说就是要满足数值存储的基本规则——高地址存放高位值,低地址存放低位值。如果图片是256色那么每个像素就得占用完整的一个字节,65535色(16位色)就得占用两个字节,以此类推。这里我们引入一个单位——bpp(bit per pixel)位每像素,这个单位和色深基本上是同一个意思只是描述的方式不一样,色深是直接指的颜色数量,bpp通过描述每个像素所占用的空间间接说明颜色数量,不过bpp这个在汉化的时候更为常用。通过以上的说明,我们就可以知道bpp和色深有如下关系:
1bpp—单色(黑白)
2bpp—4色
4bpp—16色(4bit就是半个字节)
……
bpp这个单位在以后经常会用到,其中的含义一定要深刻体会。另外,游戏中的图片格式虽说和bmp比较接近,但很多时候还是有它的特殊性的,对于图片格式的认识我们以后接触到游戏的时候再作补充,图片的现实和存储还和硬件设备由一定的关系,现在只需要大家有个感性上的认识,在作图片修改的时候还有可能涉及到程序反汇编跟踪等等复杂问题,可以说图片修改既简单又困难。
小结:本节主要介绍了图片的保存规则,游戏机图形也是像bmp这样的把调色板与色素分离开建立索引映射的。毕竟一个是电脑一个是游戏机;一个是标准的格式,是要供人们编辑使用的,一个是“隐藏”的,是只让人看得见却摸不着的,两者之间还是会有一点点差异的,比如ROM里面的图片就不会有文件头,而调色板和索引值也不是一定连在一起的。不过修改图片步骤少,容易实现,对于标准格式的图片来说新手是很容易修改出来的。所以各个初次接触汉化的玩家应该先接触一下图片的修改,而且目前修改游戏ROM图片的工具《TLP》功能还算可以,能够很轻易地享受到成功带来的刺激。另一个需要说的是“高地址存放高位值,低地址存放低位值”这个规则在两节的基础内容介绍中都反复提到过,为的就是让大家记死,几乎所有的地方都用得着,在以后的内容学习中不到万不得已将不再有类似的提示了,靠大家自己理解。至此,汉化游戏前需要了解的基本内容也就告一段落,这两节的内容讲得非常的细致是希望大家不仅能了解到这些原理,更重要的是通过这种方式的学习使大家掌握分析问题的方法。网上有很多新手都在咨询汉化需要哪些工具哪儿有下载,这是十分不好的现象,学汉化学到的不应该只是怎么使用工具来操作,原因道理才是应该掌握的内容。这两节的学习虽然没有涉及到任何游戏的内容,但讲的都是一些非常基础的东西,是容易被大家所忽视的问题,网上的教材也对这些内容讲解不够,造成很多新手知识脱节,灰心丧气的不少。在下一次,我们就将展开对游戏的分析了,游戏机样本就是任天堂的GameBoyAdvance。
四 初探篇
通过前面三节学习,我们已经掌握的一些基本原理,接下来可以正式进入汉化的研究了,仍旧采用深入浅出的方式和大家一起来探讨。
前面已经说过我们要汉化游戏不外乎就是修改文字(对于游戏配音的汉化不是业余人士能够完成的),游戏里面的文字分为两类,这两类存储显示的方式不同就决定了汉化游戏将沿两条路来进行。图片文字数量较少,修改起来相对简单直观,但需要比较好的电脑美术造诣(图1);主要方法就是使用Tile修改工具进行修改。文本文字数量巨大,特别是RPG SLG,修改相对复杂且工序多,大多数情况下都需要自己编写工具来完成(图2)。

文本文字汉化的主要流程为:字库寻找→字库破解→制作原始码表→文本导出→文本翻译→文本校验→制作新码表→字库导入→文本导入。字库破解和制作原始码表是最为关键的环节,如果这两个关卡能够顺利通过,那以后的各个环节都迎刃而解了。
介绍一下汉化最常用的工具:
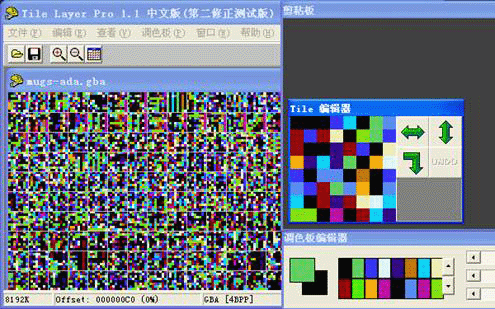
《Tile Layer Pro》——游戏图片浏览修改工具,是修改游戏中非压缩图片的利器,支持从1bpp到4bpp所有格式的文件(包括GBA)。在进行图片文字修改,字库查找的时候都会使用到它。不过遗憾的是这个工具只支持16色模式,也就是最高只能到4bpp,对于GBA256色的图片无法进行正确浏览。程序界面由菜单栏、工具栏、Tile浏览窗口、内部剪贴板、Tile编辑器、调色板编辑器组成。菜单栏放置了这个工具所有的功能项,全部的功能都可以在这儿调用。工具栏放置的打开保存还有必要的放大缩小按钮,以及Windows计算器的快捷图标。Tile浏览窗口就是最大的显示出来密密麻麻星星点点的那个窗口,这些内容就是文件里的内容,之所以没有显示出图片而是现实的“乱码”是因为游戏ROM里面的内容除了包含必要的图片以外还包含有重要的程序数据,TLP是把所有的文件内容都当成图片来显示,即便是这样我们仍然可以不用理会这些乱码”(但也不要去修改他)。
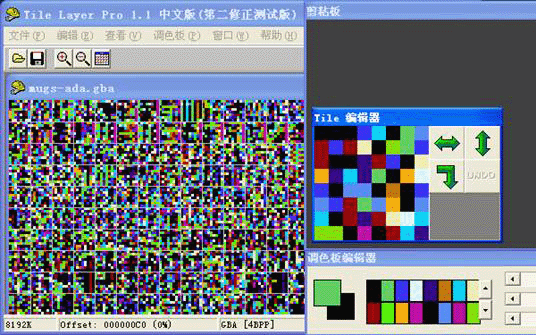
默认情况下还会显示网格线的,网格线把这些内容分为8*8的小块,每个小块就叫Tile。要注意这里的剪贴板并不是Windows的剪贴板,只能对内部使用,无法对外。Tile编辑区就是对Tile进行编辑的。在内容窗口里点一个Tile,Tile的内容就会出现在编辑区里,然后可以通过点击调色板使用对应的颜色进行填涂。TLP在显示图片的时候不是使用游戏里面的调色板(游戏里面的调色板是有程序控制的),而是使用的自身默认的16组16色调色板,所以在这里看到的图片有可能和游戏里面的颜色大相径庭。配色的时候可以在调色板编辑器里面翻页调整。当然RGB值也可以自己定义,并且可以保存下以便在以后修改的时候继续使用。虽然TLP目前不支持256色的图片,但毕竟256色的图片并不算是主导,GBA游戏一半以上都是16色图片。TLP是汉化的最为常用的工具。
《GBAmap》——TGB汉化小组自己开发的一个图片工具,针对256色图片的工具,可以浏览,替换等操作,遗憾的是不能够进行像TLP那样的直接局部修改。
《字模精灵组合器》——PGCG制作的汉化工具,针对制作码表的辅助工具,利用它可以轻易对照制作出码表文件,不过就是支持的字库类型只有比较典型的几个。
《UltraEdit》——最好用的16进制编辑器,对于汉化也是必不可少的东西。与此类似的还有《Translhextion》,里面包含有重要的功能——相对搜索。
《Paint》——其实就是windows里面的画板,当然是用来做图片修改的,简单的缝缝补补还是没有问题地,不过比起《PhotoShop》老大来说就相形见绌了。
《Relativeful Search》——差值搜索器,查找文本的时候必备,如果使用的TranslHextion,这样的工具就没必要了。与此类似的还有《增强差值搜索器》,阿一编写的,中文好用。
《Script Extractor》和《Script Insertor》——文本导出导入工具,做好码表后就得把文本导出来进行翻译,翻译完后就得再导入回游戏,如果自己不会编写程序的话就得靠这个。类似的有《菜鸟》,菜鸟小生(一只会飞的菜鸟-_-b)编写的,选择的理由是中文。
《Counter》——文本字数统计工具。翻译好的文本就得统计处字数,然后再根据实际情况判断是否要扩容(大都需要)。另外一个用途就是列出文本中所有用到的标点、符号、字符,做新码表的时候需要。
《FontTile》——做字模的工具,对于文字量小,字体要求特殊的地方适用。如果要创建大量的字模还是自动动手吧DIY。
《No$GBA》——GBA的模拟器+调试器,做ASM必须得用,类似的有《BATGBA》,当然这些工具在兼容性上还是和VBA有差距的。具有讽刺意味的是《No$GBA》这个软件在创作当初是免费提供的,从名字就可以看出来No dollar,不过发展到后来却大张旗鼓地收钱了,价格不菲哟。
《VisualBoyAdvance》——赫赫有名的GBA模拟器,汉化的时候也不能离开他,虽然本身的调色器并不强,但兼容性一流。以上这些工具是最为常用的,其他得还有很多很多,具体问题还得具体分析,那款工具更适用还得结合具体的情况来看。这些软件都是汉化高人自己编写的小程序,在性能上当然无法和大的软件工程相比,遇到一些运行错误在所难免,所以就没有必要再使用的时候刁难这些工具了。在各大汉化小组的网站上都能找到这些工具。汉化绝对不是使用工具的过程,很多东西都是无法通过工具去完成的,得依靠自己的大脑依靠自己的双手。
小结:汉化需要工具来辅助,但绝不能依赖于工具,汉化的主体仍然是个人。虽然目前的小工具小软件数目众多,但面对浩瀚的游戏来说也只能算沧海一粟,在学习汉化的过程中最好也同时学习一门计算机高级程序语言比较好,在很多时候都没有现成的工具可以使用,得自己编写一定的程序来辅助完成汉化。不用学得太深,会点三大结构、基本语句、输入输出就够了,这里推荐使用Basic语言,开发平台可以用微软的VisualBaisc系列,VB开发的程序运行效率虽说不算太高,但编写的效率快,对于汉化这样的小工程绝对足够了。
五 图形篇
上节课我们做好了汉化前的准备工作,也介绍了不少的汉化工具,接下来就可以真正面对汉化了,再强调一次,汉化不仅仅是靠使用工具就能完成的。
我们先从最简单的图形修改开始。图形修改相对来说直观,修改后很快就能看见效果,我们所用到的主要工具就是上次谈到的《TileLayerPro》(以下简称TLP),界面我们基本上熟悉了,再对几个细节说一下,状态栏里面最左边的数字表示文件的大小。
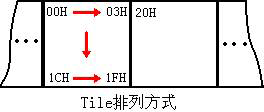
Offset是偏移地址,这个地址指的是左上角第一个像素的地址,修改的时候离不开这个地址值。右边的表示显示的模式,这里表示GBA模式。操作主要靠键盘和鼠标,鼠标就不用说了,反正就是点击。键盘翻页键可以上翻下翻整个窗口的内容,实现快速定位;键盘方向键可以控制图形以Tile(碎块,就是被网格线分开的一个个小块)为单位上下左右移动,实现粗调;按住键盘Ctrl再按上下左右以像素为单位移动图形,实现微调。每个Tile在显示的时候像素的地址从左到右从上到下依次增高,在GBA 4bpp模式下一个像素占用4个位,每两个像素占用1个字节,所以一个Tile就占用0.5*8*8=32个字节;图形框里面的Tile从左到右从上到下地址也是依次增高的(图)。
理论结合实践,我们这就来尝试一下,从最简单的入手,以《Sonic A2》为实验对象,以开始界面中间的那排白色的日文字符为目标,翻译成中文应该是“请按START键”(之所以不以顶上的“ソニック”为修改对象一是因为这个图形是256色的用TLP无法修改,二是因为这个图案修改起来需要有电脑美术创作能力)。

找图片有两个方法,最直接的莫过于直接用《TLP》打开游戏ROM,用肉眼从上到下地直接观察整个ROM,在ROM的中部某处就能找到这个图形。
这个方法非常的快,但毕竟要靠肉眼盯着看,一是容易漏掉,二是万一ROM中多次出现相差不多的内容就不知道该是哪个了,还得一个一个地改着看,麻烦。
我们学习另外一种更加有效的方法——搜索法。
我们所使用的模拟器别光认为他就只能模拟GBA游戏,VBA这个模拟器不光能模拟游戏,还有一些基本的调试工具,这对汉化来说提供了极大的方便。模拟器执行游戏也是模拟的游戏机机能,GBA卡带里面的游戏内容本身就是固化在内存里的(GBA卡带其实也是内存,只读内存),模拟器在执行ROM前首先会把ROM文件里面的信息读取到内存0x08开头的一块区域里面(相当于插入GBA卡带),然后再执行代码的。要让图形出现在屏幕上就必须先把数据传送到显存(0x06xxxxxx)当中,了解了这个原理我们就从显存中找到图片的二进制数据,从而就可以在ROM中搜索出准确的位置了。
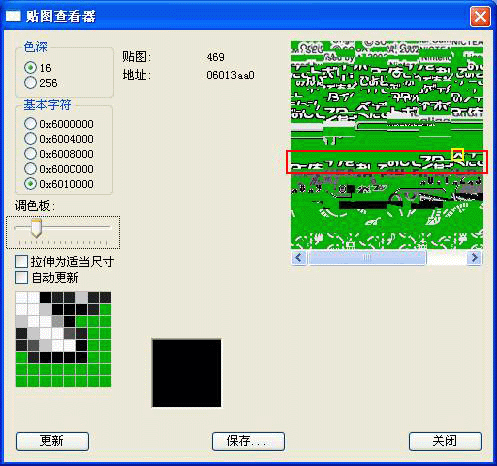
首先,用VBA打开这个游戏并运行,一直到出现这个游戏画面,再依次选择“工具”、“贴图查看器”出现一个窗口。窗口默认情况下以16色来显示显存中的图片,位置在0x06000000,色深我们不用去改他,本来就是16色的图片,依次改变基本字符下面的选项,直到出现我们想要的图形。每次运行时显存内容都可能不一样,我是在0x06010000找到了图形的残像,虽然文字很乱但基本上就是这些了,图片被分割成了几十个Tile,Tile在这里是不会被重组的,从左到右从上到下依次排列。拖动一下调色板滑竿让我们看得更加清晰,仔细看一下就会发现中部的那些Tile就是我们要改的内容(红框部分),我们随便选取一个Tile(黄框部分)。对话框会返回两个值:贴图、地址,贴图我们暂时不用去管它,记下地址这个值,关闭这个对话框。再进入工具里面的“内存查看器”,输入刚才的那个地址然后回车,马上就会跳到这个地址了0x06013AA0(输入的时候不用敲入“0x”),这些值就是刚才我们选的Tile的二进制值。
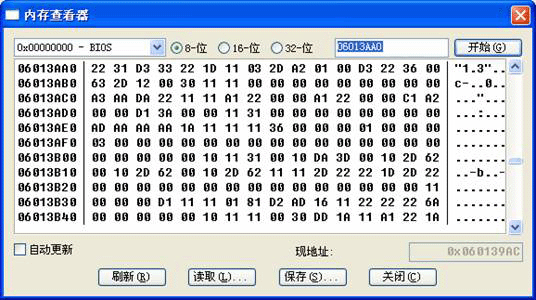
接下来用16进制编辑器打开这个ROM,使用16进制查找(UE的快捷键为ctrl+f)“2231D33322”这一串数值,查找的数值越多,找到的雷同可能性就越小。搜索出来一共会有3个结果,位置在5D9A70H、5DAFB0H、6C6250H。正常!因为这个图形在ROM中本来就保存有3次,到底该是哪一个逐个修改看看就知道了,这里该怎么操作,请大家自己想一想、做一做,很简单的。运气比较好,第一个地址5D9A70H就是我们想要找的,记下这个地址。回到TLP下,按Ctrl+G,输入这个值跳转到这个地址下马上就可以看到内容了。

在这里显示出来的仍然是不会重组的Tile,游戏里面是通过程序指令来重组这些Tile的,假如这种Tile很多的时候这样看起来确实非常的累,最好编写程序来实现Tile重组,以便于我们察看,所以一开始我就建议大家要学会编程,道理就在这个地方。这种小程序熟练后顶多10分钟就可以搞定的。
从这些Tile上看来并不完整,我们进行一下左右调整,当所有需要的图形Tile都出现后就可以数一下有多少Tile,计算得到整个图形是23*2Tile的,所以像素就是184*16。
接下来我们可以导出一小块Tile,以这个Tile作为母板描绘汉字。导出图片的方法是先用鼠标右键框选一个矩形反色框,然后选择菜单里面的“编辑”-〉“导出位图”保存为bmp格式文件,之后就可以使用画板,Photoshop之类的图形编辑软件修改了。
修改的时候注意几点:我们之所以要导出一些Tile是为了从这些Tile上取RGB值,因为我们不能另外创建新的颜色,否则在导入后颜色会发生偏移。修改生成文字的颜色要和原文字相对应,原文字的主体色是什么修改后的也必须是什么,阴影色背景色这些都要一一对应。
由于TLP是按顺序显示Tile的,不可能对图片进行重组,所以导入得时候还得按照原来的顺序导入。在画板里面描绘中文字BMP图片的时候还是可以不必考虑顺序问题,导入的时候先把图片导入到一个废的文件里,然后再从这个废的文件往游戏ROM中导(借助剪贴板粘贴复制),这一步注意一下顺序就可以了(TLP支持多文档)。
一般来讲我们在把日文变为中文后字符长度都有一定的缩短,为了使修改后的中文仍然会出现在屏幕中央的位置我们就得注意一下文字在图片中的位置,为了方便居中对齐,我们在修改文字的时候要把画布的大小调为原来图片的大小,针对这个例子就是计算得到的184*16,然后再在这个区域里居中,完成后再把整个图片完整地导入,包括所有的空白部分。
导入完毕保存后我们就可以在模拟器里面运行看看效果了,千万不要激动,要使用VBA重新打开一次ROM,而不是Ctrl+R复位。
这是我做的导入ROM后的样子和游戏中的效果:


小结:
这一节主要是操作方面的知识,没有什么原理基础,估计大家看完后一片茫然,的确,光看是不顶用的,经验是要靠实践来积累的。
初次修改游戏大家一定会遇到问题(如果没有我拜你为师)具体该怎么解决仍然是留给大家继续思考的问题,自己研究出来的比别人教给你要深刻得多,不仅完善了自己的知识,更锻炼了自己的能力。另外游戏画面中能看到的内容一定能在显示内存中找得到,但在显存中能找到的图形并不一定能在游戏ROM里面找得到(这里的显存指的是游戏机的显存,也就是VBA中0x06xxxxxx这块内存区域而不是电脑显卡上的内存),很多情况下由于图片过大,游戏编写者会采取一些特殊的方法来缩减图片所占用的空间,或者为了其它某些目的而采用其它的存储方式,往往这些图片是靠程序处理生成的,就无法直接地在ROM中找到了,需要学习ASM破解后才能跟踪并修改。
《索尼克A2》这个游戏里面能够使用TLP直接修改的地方相当的多,是一个很好的修炼对象,大家珍惜。
番外篇 汉化美工教程
第一章 概述
Lesson 1-1 什么是汉化美工?!
欢迎大家来到PGCG汉化教室听我闪.纯静水的美工第一课——什么是汉化美工。
顾名思义,汉化美工拆开来讲就是为汉化工作进行美化的工人(工程师)
Lesson 1-2 汉化美工的任务是什么?!
一个游戏如果要完美汉化,不仅在对话上要求将外语中文化,还要将出现在游戏当中的其他外语汉化过来,例如游戏开始的LOGO、游戏当中的菜单、按钮等等一些非文本文字,甚至包括游戏当中出现的“Ready!Go!Winner”等等非汉字字眼也要将它变成中文的文字。换句话说,只要是在游戏中以非文本文字形式出现的外文,在合理的情况下我们美工就要有义务将它汉化过来。
当然,这样的任务也不是完全绝对的,也有一些特殊的情况。例如大作“FINAL FANTASY”系列,这样如雷贯耳的名字,配上绝世插画家天野先生的亲笔插画作为游戏LOGO的衬图,我们美工就不需要将它变成中文的了。不是没有能力,而是没有必要,FINAL FANTASY已经在大家心目中深深地扎下了根,我们美工作为汉化界美学的代表,没有理由将这种完美硬生生地破坏。还有一些其他的状况,比如足球游戏中进球后“GOAL!”、以及一些专有名词等等,我们都不能改变它,因为这是定律,破坏它改变它就等于破坏了改变了这个定律,是不符常规的。所以,我们在汉化的过程中,尽量避免汉化这类词语,要知道:保留原始美也是有道理的。这样说来,美工的任务就是汉化所有非文本文字以及字库字模的并使之美化。
Lesson 1-3 为什么要有汉化美工?它存在的意义是什么?说了半天美工,到底为什么会有这样的一个职务出现呢?汉化美工的存在到底有什么意义?
以往大家在玩汉化游戏时都会看到汉化小组(个人汉化除外)的职务表:ASM、破解、翻译、测试……等职务,哪里有什么美工呢?要美工是不是画蛇添足?我要说NO!!大家如果留意的话,现在出现的任何一款汉化游戏几乎都不能说是完全汉化的,也许这样说有一些刻薄,但是如果将游戏中未汉化到的部分也汉化过来,我想当今的汉化界又将是一种面貌。大部分游戏的汉化度确实已经很高了,所差的就是这么一点点,包括LOGO汉化、按钮汉化以及字模的优化。如果将上述内容一并汉化了完善了,我想玩家才会更加喜爱我们的作品。所以我希望更多的美工投入到游戏汉化界里来。
第二章 基础认识
*注意*不管做什么事情,牢固的基础是成功的关键。所以希望大家能将基础打牢。
Lesson 2-1 汉化美工必备的汉化工具
作为一个将赴战场的战士,没有武器是坚决不行的。汉化美工也是一样,没有汉化工具作为武器,简直就是天方夜谭。不管是别人已经做好的现成工具,还是自己用编程本领自己编的工具,都是很好的杀敌武器。我们必须掌握这些武器的用法,理解+实践,才能熟练掌握,运用自如。
我不是编程人员,也不懂什么计算机语言,所以在此我们不考虑自编的汉化工具,之来研究一下现在网上流传的汉化工具(仅做举例推荐)。
1.TLP
2.PhotoShop
3.VBA
4.No$GBA
5.UE
6.FontTile(辅助)
7.Fonts(辅助)
……
Lesson 2-2 工具概述
1.TLP(Tile Layer Pro) rom碎片整理工具,可用此工具观察游戏rom里的碎片(tile),从这里我们能找到我们需要汉化的字模、按钮、图片等,是最重要的汉化工具之一。其具体用法我们将在第三章第三节具体讲到。
2.PhotoShop(以下简称PS) Adobe公司出品的最有权威的图像编辑器,我们美工必不可少的汉化利器,它可以大批量的制作字模、修改Tile,也可以轻松修改片头的LOGO,前提是你得熟练掌握这个软件。什么?你不会?不好意思,请关闭此篇教程,打开Google,去搜索PS的基础教程吧。其实做汉化美工只要一点点的PS基础知识就可以了。其具体用法我们将在第三章第四节学习基本的使用方法。
3.VBA(VisualBoyAdvance) 最好用的GBA模拟器,用来测试我们的汉化的游戏,找bug就全靠它了。此外它还支持即时存档、截图等功能。1.5版以后的VBA还支持更换皮肤的功能。我们PGCG小组会在每款汉化成品放出的时候,同时附赠一个与游戏相对应的VBA皮肤,给大家以不同的新鲜感。我们将会专门用一节来讲讲VBA在汉化中起到的具体作用。
4.No$GBA 这是个用来追踪GBA rom里的tile的工具,它比较麻烦,在本初步教程里不做赘述。如果可能的话,我们将在进阶篇中来研究这个工具。
5.UE(Ultra Edit) 16位文件编辑器。也是比较流行的相对搜索工具,在我们美工这里则是配合No$GBA使用的利器。同样的,可能的话,我们在进阶篇中讲述UE的使用方法。
6.FontTile 任意字模编辑器。大家是不是认为有了PS,这个工具就没有太大的用处了。其实不然,对于制作8*8的小字体,PS处理出来的效果远远不及这个工具了,FontTile同样是辅助PS制作文字tile的必不可少的工具。
7.Fonts 各种文字字体。Windows自带的字库里的字体是绝对不够用的,我们还要用到文鼎、方正、金山等字库来丰富我们汉化的游戏的文字样式。
以上的辅助工具Font Tile和字体文件将在第三章最后一节给大家介绍。
第三章 工具的初步了解
本章的学习目的:初步了解汉化的步骤,以及TLP\PS\VBA等工具的使用方法。
Lesson 3-1 汉化游戏的基本步骤
1.分析rom的构造:在这一步我们要分析一下需要汉化的rom的tile、字库的构造,看一下Tile的排列顺序,字库是否被压缩,这一部决定了此款游戏的汉化难易程度。
2.查找字库:如果字库未被压缩,则确定此字库是否对应游戏中的文本文字。
3.制作码表:根据修改字库中的文字,对应观察游戏中文本文字的变化,推算出码表字符的排列顺序,做成码表。
4.导出文本:根据码表讲游戏中的文本全部到成文本文件。
5.翻译文本:将导出的日(英)文本翻译出来。
6.统计字符:统计一下文字的字数,这里指的字数是整个文本出现不同字符的种类数,重复出现的只算成一个字数。
7.重做字模:根据翻译好的文字重新制作字模,如果原先的字模数量不够,那么就要考虑扩容了。
8.导入文本:将翻译好的文本,按照重做的字模导入到游戏当中。
9.测试-〉修改-〉再测试-〉再修改……
以上是汉化一款游戏的基本步骤,暂且不涉及到诸如字库解压缩、扩容等相对高级内容,如果大家有兴趣进一步了解,可以到网上去找参考资料。
有朋友会问:“美工呢?上面的步骤中并没有需要美工的地方啊。”
别着急,美工的工作可以单独提出来做。
Lesson 3-2 美工的任务初步
其实美工的任务可直接插到以上步骤的第一步后面来做,也可以放到最后来做。这就是仁者见仁,智者见智了,根据自己的爱好随意而行了。
如果与小组其他的成员有分工的话,那就更好了。破解、翻译、美工同时进行,这样汉化的速度就更快了。
我们美工拿到rom,首先要使用碎片编辑工具——TLP整理可看见的非文本文字tile以及未压缩的字模。将所有需要汉化的tile整齐的排列出来,方便汉化。
整理OK后,逐步导出tile词组或句子转成位图,再利用PS汉化编辑,然后将做好的tile再导回原位,保存后进入游戏就可以看到效果了。
说起来容易做起来难,下面我们就来详细地了解一下我们的武器:TLP。
Lesson 3-3 初识Tile Layer Pro V1.1(TLP)
现在我们来打开碎片编辑工具TLP。我们用0555号rom 《Mr.Driller Ace(J)》(钻地小子A日版)做辅助教材材料。
选择菜单栏下File-〉Open...(或者按快捷键Ctrl+O),打开钻地小子A(以下简称钻A)的rom。这时我们会看到TLP的主界面上出现了4个窗口。我们现在就来来看看它的界面。
大家来看,和其它软件一样,TLP也有菜单栏、快捷键栏、主窗口、状态栏……
首先看看主界面上,序号一那个花花绿绿的格子就是观看Rom tile的窗口,我们要找的汉化信息就在这里,我们暂且叫它ROM 主视窗。序号二Tile Arranger是用来排列左边tile顺序的,大家都有玩过拼图游戏吧?这个窗口就是了。不过依我看这个窗口简直就是鸡肋,多此一举,我们将来会介绍更好的方法排列tile的顺序。序号三Tile Editor是用来编辑单个tile的小窗口。我们可以在这里像用window自带的画图工具一样简单,左键是前景色,右键是背景色。我们在ROM主视窗里选择的tile可以在这里随意修改。序号四就是调色板了。在TLP里只能观察16色的tile,这个调色板就只有16色。大家看到调色板里那上下两个箭头了吗?他们是切换调色板颜色方案的。一共16个方案,共256色。我们通过更改方案来使主视窗里的tile更加清晰的显示给我们。
下面是菜单栏:File(文件)下,Open...(打开...)、New...(新建...)Close(关闭当前rom)、Save(保存)、Save as...(另存为...)、Exit(退出程序)。这些不用我细说了吧?
Edit(编辑)下,Undo Drop(撤消)、Copy(拷贝)、Paste(粘贴)、GOto...(转到...)、GOTO Again(重复 转到地址)、Import Bitmap...(导入位图)、Export Bitmap...(导出位图...)、Clear Arranger(清除排列窗口)。
这里要强调的是:Goto...大家看到TLP软件最下面的状态栏了吗?那个Offset:********
就是当前tile在主视窗里的位置。我们可以通过Goto...来直接跳到我们需要到达的tile位置。
Goto Again则是重新回到刚才所转到的位置。Import Bitmap和Export Bitmap是导入导出位图,便于修改大范围的tile。这个是配合PS的重要命令,大家要好好的记一下。Clear Arranger是清除Tile Arranger窗口里排列的tile。
Vies(查看),Zoom(放大镜)、Format(格式)、Gridlines(格线)。Zoom可以将tile的观看大小放大1-4倍,一般程序默认为3倍大小。Format则分为1BPP、NES、Game Boy、VirtualBoy、NGPC、SNES 3BPP、SNES、SMS、Genesis、GBA 10个格式。分别观看不同机种的rom,我们在这里只选择最后一个GBA格式就好了,其他的不作考虑。是否勾选Gridlines则影响到主视窗里的格线是否显示。
Palette(调色板),在这里我们可以选择TLP程序自带16种方案以外的调色方案。其实一般来说,TLP里自带的16种方案足够使用了。
Window(窗口)和Help则不必去仔细研究了,没有一点必要。忽略忽略...
TLP的初步认识到此结束,我们将在进阶篇更深一步的研究TLP。
Lesson 3-4 PhotoShop 6.0
作为美工如果不会使用PS等于写字不会拿笔一样。PS的知识面很广,但使用在汉化里,只用学会少许的基础知识就行了。下面我们来看看PS的界面,我会针对我们所用到的命令和按钮做一些讲解的。
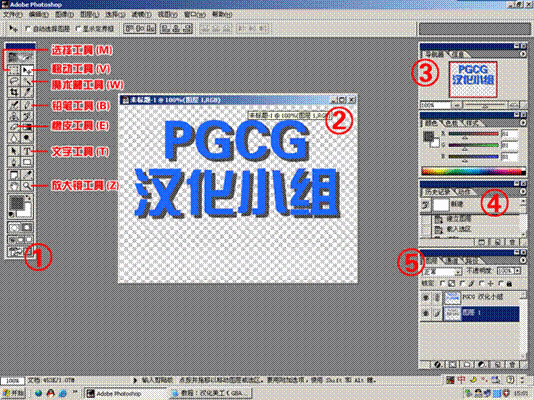
序号一:工具栏
选择工具,也可以成为框选工具,是用来选择图像像素的工具,所选图像会被虚线圈着,虚线内的部分处于修改状态,虚线外的部分则不会被修改。(快捷键是M)
现在我们要说一下PS的编辑对象,图像处理软件一般针对两种图像格式,一种是矢量图(ve-ctor):矢量图使用线段和曲线描述图像,所以称为矢量,同时图形也包含了色彩和位置信息;另一种就是位图(bitmap)了:位图使用我们称为像素的一格一格的小点来描述图像,计算机屏幕其实就是一张包含大量像素点的网格。换句白话说:如果无限制的放大两种图像,矢量图永远保持平滑;而位图则会由于放大而变得出现锯齿、马赛克、模糊不清。但是矢量图表现出来的画面单调,即使色彩艳丽也是用各种颜色的色块堆积而成;位图的优点就是色彩鲜艳,如果正常显示位图,它则会将以最好的效果展现给大家。用来编辑矢量图的软件有CorelDRAW、Illustrator、以及大家熟悉的Flash。用来编辑位图的软件则有Photoshop、Painter等(不过从PS6.0开始,PS也可以编辑矢量图了)。
我们汉化美工需要掌握的就是关于位图的知识。如果有可能的话,掌握矢量图也会对我们的汉化工作起到事半功倍的成效。
移动工具,用来移动所选择的对象,如果有框选的内容将会只移动所选择的内容,框选外的则不再移动工具考虑之内。(快捷键是V)
魔术棒工具,用来选取颜色相同或近似的图像。根据容差值的改变,选取的范围则会做出相应的改变。容差值越大,选取的范围越大,反之则反是。(快捷键是W)
铅笔工具,和Windows自带的画图工具里的铅笔工具一样,根据笔刷的大小可画出不同大小的点或线。(快捷键是B)
橡皮工具,就像现实中的橡皮一样,可以将图像擦除掉,起到与铅笔工具相反的作用。(快捷键是E)
文字工具,输入文字的工具,可以改变字体和字号,还可以根据需要修改字距与行距。用来输入大量的文字比起用TLP来画要方便简单的多。(快捷键是T)
放大镜工具,不用我说大家也应该知道。用来放大和缩小图像的显示大小。(快捷键是Z)
关于图像的大小显示问题还有一点补充要说的。双击放大镜工具会使当前图像以正常比例显示,而双击放大镜左边的抓手工具(快捷键是H)则会将当前图像按屏幕大小显示。大家要学会或用这一技巧。
序号二:工作区
就是制作或者修改图像的视窗,你对图形所做的任何修改都在这里体现到。
序号三:导航器和信息栏
导航器,就是一个工作视窗的缩小图,在导航器里,你不仅可以浏览到图像的全貌,同时可以用鼠标点击里面任何的地方,也此同时,工作视窗里的位置也会相应移动到你所点取的地方。
信息栏,里面反馈了图形中颜色的信息,我们常用到的也只有色调RGB和位置XY。
序号四:历史记录
从这里可以看到你对图像所做过的任何一步,一般定在20步内。
序号五:图层
PS最重要的部分之一,简单的举个例子来说:你有一张纸和N张塑料玻片,这张纸就是PS里的背景层,而这些塑料玻片就是图层1、图层2……一张一张摞在背景层的上面。
活用Photoshop对于汉化的美工部分非常重要,谨记。
六 文字篇(一)
随着对汉化理论的逐步理解与掌握以及对经验技巧的掌握,本教程所涉及的内容也会渐渐加深、渐渐拓宽。前面几节相信大家已经懂得了如何修改游戏中的图片内容,这主要是借助现成的工具加上一点点耐心傻瓜化地修改来完成的。有很多对汉化抱有热情玩家都只能停留在修改图片上,其原因大家也能想得到。仅仅掌握了修改图片的方法也还远远不够,游戏发展到今天基本上没有哪个游戏的文字就纯粹是采用图片来存储的了,了解文字显示的核心至关重要。从现在开始接触的东西对大多数人来说才真正感觉到难度。希望大家既不要骄傲自大,也不用妄自菲薄,万里长城也不是一天建成的,既然大家对汉化有如此的热情就一定要对自己充满信心。
在教程的最开始就谈到了文字在游戏中是如何存储显示出来的:游戏文字信息通过将文字编码、文字点阵信息分离并保存到游戏文件中,显示文字的时候程序先读取表示句子组成文字的一序列编码,然后根据游戏自身独有的字模转换程序通过编码计算出字符点阵的物理地址,然后再通过一系列的显示程序把该字符点阵显示到屏幕上。

我们知道了基本过程后就不难猜想到,既然要修改文字我们还是可以通过修改点阵来实现。例如句子“I love China!”,可以把字符点阵“I”改为“我”;点阵“l”改为“爱”;点阵“o”改为“你”……以此类推。句子就被改为了“我 爱你,中 国!”,多余的字符就全部清除。理论上分析了,我们先来找个游戏进行一下实践——《光明之魂II》

我们就来修改一下图片上顶部出现的那句话,按照字面意思可以修改为“请选择一名角色”。通过我们前面所掌握的修改图片的方法很快就能找到这些文字的位置,用TLP定位到0x8DC068,这里就是第一个字符“キ”的位置,我们可以看到该字符由4个TILE构成,排列顺序为[左上][右上][左下][右下]。
在前面就已经说过图片之所以会出现错位这并不是由于TLP软件的错误造成的(TLP永远都是顺序显示的),这个和游戏显示程序的设计有密切的联系,但具体为什么需要这样排列的这并不在我们讨论之列,我们需要做的仅仅是按照原先的顺序排列好修改后的字符就可以了(字符的描绘可以使用任何一款图像处理软件中的文字工具来制作)。
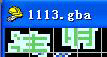
经过导出导入修改等一系列过程,这个字符被修改为了“请”字。其他的字符按照这样的方法依次修改,修改完后用VBA模拟器预览效果,可以看到这样的画面:

看来这样子做是相当成功的!见到了这样的成果你心情将会如何呢?
高兴之余静下心来还是会发现一些问题,如果把“キ”改为“请”的话,游戏中所有出现了“キ”字符的地方都变为了“请”,但“キ”并不是“请”的意思。如果全都都照这样子修改的话,一两句还是可能实现,要是句子多了绝大部分句子就要混乱了。所以仅靠这样子的修改还不行,我们还得调整每个字符的排列顺序甚至出现的位置。我们再来看看字符显示的全过程,程序是先从文件中读取了句子文字的编码串然后再经过一系列程序才显示出来的,换句话说编码串就决定了字符的排列顺序,要改变文字的顺序就是要改变编码串中各个编码的顺序。例如:先假设01表示“A”、02表示“B”、03表示“C”,句子“ABC”对应的编码是010203,如果要改为“CBA”的话我们就可以把“010203”改为“030201”。明确了这个道理,我们就必须找到句子对应的编码串在游戏文件中的具体位置,但我们事先并不知道每个字符对应编码,而且每个游戏的编码都不尽相同,所以也不可能根据经验来判断,缺少了这些关键的信息我们就无法搜索出编码串位置。于是我们的首要任务就是先找到一些字符的编码,然后就可以顺藤摸瓜测试出其他字符的编码。但问题是如何知道字符编码?这是一个巨大的难题。在开始找到“キ”字符后,留意一下就可以发现一些线索:基本上所有的文字点阵都保存在“キ”字符点阵附近的一大块区域内,而且字符和字符之间并没有其他杂乱信息,看来设计人员是把整个游戏出现的字符都放在了一起。那么这些点阵字符的首地址就很有规律了——公差为128Byte,因为1个4bpp的Tile占用的是32Byte的空间,一个字符需要4个Tile。前面也说过,编码是用来计算字符点阵的物理地址的。至于使用的什么具体公式我们并不用去在意他,我们可以导出一个抽象公式来理解:
点阵地址 = 字库首地址 + 偏移地址
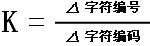
偏移地址 = 比例常数 * 字符编码 + 偏移量
比例常数 = 点阵大小 * K
所以: 点阵地址 = 字库首地址 + 点阵大小 * K * 字符编码 + 偏移量
对于同一游戏来说公式中的字库首地址和偏移量都是一个常量,唯一的变量就是中间的一段,由此看来点阵地址和字符编码是成线性对应关系。而我们恰好可以查看得到等号左边的点阵地址。把上面的公式通过一些数学上的变形可以得到:

△点阵地址 可以写成△字符编号 * 点阵大小,所以又可以得到:(△字符编号就是两个字符点阵的序号位置差,单位为“1”)
△字符编号 可以轻易知道,而系数K在同一个游戏中是一定的,并且公式里的其他参数全都为整数。△字符编码 一定大于或等于 △字符编号,因而K小于等于1。点阵大小就是每个字符点阵所占用的空间,这个例子就是128。(还不至于哪个游戏设计者喜欢自我拔高到利用二次函数来计算吧-_-b)。只要能知道K的具体数值我们就能知道 △字符编码了,再接下来就可以通过相对搜索来得到句子的物理地址咯。
准备好一个相对搜索工具,比较好用的是汉化高人“阿一”制作的《增强差值搜索器》和一个《字模精灵组合器》,最后再理解一下上面的推导过程。这一节先到此为止。
小结:本节开始正式涉及到文本文字的修改,内容逐步变得难以理解,光看不实践是绝对不行的。文本文字的修改要比图片修改更加的困难,很多时候都得靠灵活的方法才能对付。大家有了一定实践基础以后很容易犯迷糊,误以为每个游戏的文字都能按照这样的方法修改,我一直都在强调,游戏不可能一层不变。这一节中虽然提到了几个数学公式,如果你对数学不太了解,也不用去在意几个公式怎么得到的,只要你能知道地址和编码成线性比例,有这个意识就可以了。我在这儿之所以要这样提也是为了告诉大家要调动自己所掌握的其他相关知识来思考问题,一个人的知识结构应该是网状的。这不仅包括电脑相关知识,凡是能用上得都可以用上来,万一此路不通还可以通过其他知识换个角度来思考。细心的人也许会注意到“キ”字符修改为“请”字符后颜色数变少了,没有了蓝色。我来解释一下:对于大字符(一般来讲8*8的字符叫小字符,除此之外就算大字符)外观看上去比较粗大,如果只用一种主色再加上一种阴影色的话会使字符看起来有明显的锯齿,特别是对于笔划比较简单的字符(GBA可没有全屏抗锯齿功能哟)。所以游戏设计者会采用一些辅助色来对字符的拐角进行前景和背景的过渡。不过这对于笔划相对比较多的中文汉字来说用不用过渡效果并不是十分明显,如果再增加字符光滑的处理的话汉化的成本(主要是时间,时间就是金钱嘛)就太高了吧。除非你有特殊要求,否则就没有必要这么做了,一般都是采用一种主体色加阴影色在加背景透明色来做汉字字模了。
七 文字篇(二)
字符的点阵地址和编码的关系你都理解了吗?如果已经比较透彻了就可以继续研究了。上次我们提到了这个公式:
从实际出发,我们可以从TLP中观察字库来计算出编号的差值,而K从表面上来看我们只能确定的是一定小于等于1,所以就需要对K进行一些猜测。接下来介绍一下什么叫相对搜索:相对搜索就是指不知道具体的搜索值,而只知道几个值之间的差(例如:a b c 三个数,我们事先并不知道这三个数的具体数值,只知道a-b=5 b-c=6),因此我们就利用这其中的差值作为条件来进行搜索,这样的搜索方式就叫“相对搜索”(或“差值搜索”)。比如搜索条件是“0,5,6”,可能搜索出来的结果有很多个,像“0,5,6”、“2,7,8”“10,15,16”等等。这种相对搜索方式正好适合我们所知道的条件。先来看看搜索工具《增强差值搜索器》:
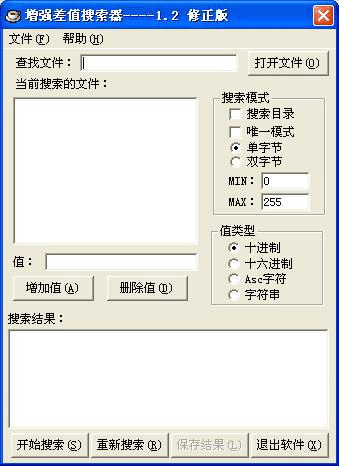
全都是中文化的,傻瓜式的操作没啥需要特别说明的地方。
下面我们来找找上一节中《光明之魂2》里的那句话“キャラクター……”的位置。
首先我们打开TLP定位到字库的范围内,使窗口左上角第一个Tile位于字库的最开头,经过观察得知那个圆圈A就是字库的开头。将这个字符的第一个Tile出现在左上角位置(记得微调的时候使用[Ctrl]+左右),并记下这个位置的地址0x8D94E8。

接下来打开《字模精灵组合器》工具,并打开GBA文件和一个调色板文件(用VBA随便导出一个吧,只要能看清楚就行)。然后再在起始地址框中输入开始记录的地址,不过需要注意的是这里需要输入的是10进制地址,把开始记下的地址先转换一下(使用科学计算器吧)得到9278696。因为字符是16*16的结构,所以在窗口右边选择“16*16 1”模式,点击“显示”后出现这样的画面:
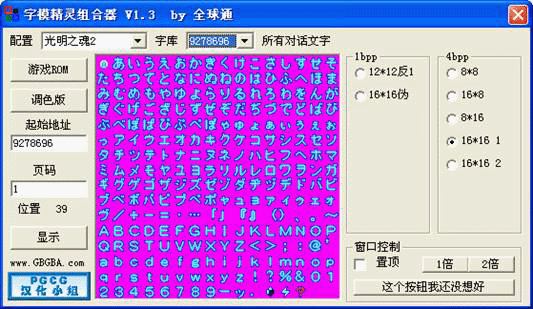
我们需要利用这个工具来计算字符序号的差值,虽然我们不知道每个字符的准确序号,但公式中只需要差值就可以了。窗口左边的位置可以帮我们计算出差值,只要把鼠标指针悬停在字符上就可以出现这个字符的相对值(相对于左上角第一个字符的值)。首先把鼠标放到字符“キ”的位置上得到“位置 57”记下来,接着是第二个“ャ”得到“位置 98”,依次类推。最后得到的记录是“57 98 77 58 60”。接下来切换到《增强差值搜索器》的窗口。其中“搜索模式”我们先来试试“双字节”,我们记录下的是16进制值,所以“值类型”选择16进制,其他地方先暂时不用去改变它。最后剩下“值”这一栏就是填写差值的。在上面的公式中我们缺少的K值只能靠猜测得到,最简单的猜法就是设想“字符编码”的改变量恰好为“字符序号”改变量的整数倍(再怎么说程序员也不会清高到使用浮点吧),最简单的整数倍就是1。既然如此我们就先假设“△字符编号”等于“△字符编码”,于是在“值”这一栏中依次输入“57 98 77 58 60”,输入一个数按一次添加,最后点击最下面的“开始搜索”。稍微等一会儿,“搜索结果”里面就会出现一些搜索出来的结果。
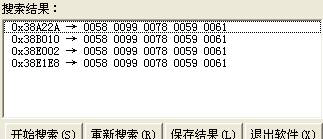
最左边的表示结果的地址,箭头右边的表示从该地址开始的文件的真实内容值(16进制),我们可以清楚地看到搜索出来的结果每两个数之间的差值刚好和“57 98 77 58 60”一致,现在你应该更深刻地体会到什么叫相对搜索了吧。不过还是不要欢喜,因为我们一开始就是假设的K=1的,倘若K不是1,那么我们找到的并不是正确的地址,况且现在一共出现了4个符合我们条件的地址。所以,再接下来就应该验证一下这些地址到底是不是我们想要的。至于怎么检验我就不多提的,基本方法就是利用UE编辑器对这4个地址的内容逐一修改看效果(注意备份)。运气十分的不错,我把0x38B010这个地方向后延续的几个值都改为了58H(用双字节表示)

保存后,接着在模拟器中打开,出现了如下结果:

屏幕上相应地也出现了4个“キ”,这总可以庆幸一下了,呵呵。
庆幸完了再来看看刚刚修改的内容,你应该能明白0058H是什么意思了吧?不错,那就是“キ”字符所对应的编码。千万不要放弃这个关键位置,很多信息就得靠他来提炼出来呢。把 00 58 改为 00 59 ,在屏幕上又出现了“ク”字符,对照《字模精灵组合器》所显示出来的字库,由此看来“△字符编号”和“△字符编号”的确相等,我们猜测的K=1是完全正确的。既然我们得到了“キ”字符的编号又知道K=1,想要知道其他的字符的编号就迎刃而解了。看到这里你已近会改字库也会改文字编排了,理论上你已经具备了汉化游戏的基本能力了。了解了这么多信息后,你还需要整理一下整个游戏的文字情况。就是查清游戏哪些地方使用的是图片文字,哪些地方使用了文本文字等等信息。这些信息也是至关重要的,千万不能省略这些细节方面。
小结:这一节内容主要讲解了如何利用相对搜索来获取字符编码的过程,其分析过程比操作过程更为重要,因为这一部分内容很多时候都带有一定的猜测,一旦猜测不好的话结果是不会出来的。而且这里的猜可不是脑筋急转弯那样胡乱猜,必须经过事先的一系列分析才可以,反正尽一切可能从文件中多提取信息。甚至有时候还需要通过模拟器搜索内存的值,如果你对游戏动态修改比较在行的话,在搜索文字编码的时候还可以想到另外一种方法,就是利用《金山游侠》《EmuCheat》这些工具来查找内存值的变化,从内存中或者游戏的存档.sav中有时候也能有所收获的。在这里就不提供具体操作方法了,提示一点:很多游戏在开始的时候都需要输入玩家姓名的。虽然这种方法只能搜索出文字的编码,但只要把每个字符编码都确认后再把句子字符串转换成编码串来查找(这里当然是UE的普通搜索了,头脑一定要清晰)。在实际操作过程中大家一定不可能像这一节介绍的那么顺利,因为这是教程,所有的材料都是事先设计好了的,就连猜的K=1也是如此,所以大家遇到困难是很正常的,要平常心对待。另外还需要补充说明一下关于那个K的问题——K其实可以理解为字符编号和字符编码的关系,多想想就不难知道“△字符编码”一定是“△字符编号”的2n倍。说得具体点,仍然以“キャラクター……”这句话,开始我们假设为K=1,所以得到“57 98 77 58 60”,如果这样子搜索不到结果就设K=1/2,得到“AE 130 EE B0 C0”,还搜索不到就设K=1/4、1/8等等依次类推。搜索的时候还得注意尽量多添加几个字符来作为搜索条件(一般5-7个字符),并让几个字符距离不要太远(太远了不便于计算)。有些时候编码并不一定只采用单字节或者双字节的单一编码,单双混合编码也很常见,程序员喜欢把英文字符和日本假名设计成单字节再把日文汉字设计成双字节(例如《SD高达》),所以搜索的时候也要注意搜索的字符最好属于同一类型的。搜索方法是多种多样的,大家灵活一点还能想出更多更多。
八 文字篇(三)
在掌握字库修改和编码查找文本修改后基本上就掌握了游戏机游戏汉化的原理了,但仅仅懂得原理也还不够。虽然我们会使用《TLP》《UE》等这些工具来修改游戏,但这些工具的初衷并不是针对汉化设计的,面对如此多的文字内容要一点一点地人工修改,即便是神仙也会感觉到累,因此我们就有必要命令电脑来帮我们做一些规律性的操作(我很嫉妒电脑有光速一般的计算能力)。例如文本脚本的导入导出、中文字库的生成等等。
下个定义:文本脚本——文本内容依照指定的编码所对应的十六进制数字串。例如上一节找到“キャラクター……”的脚本“ 58 00 99 00 78 00 59 00……”。从这一段的特征上我们可以判断出“0058”对应“キ”、“0099”对应“ャ”等等,依此类推就可以得到该游戏的全部文字编码。得到了所有文字的编码后就可以编写程序,让电脑帮我们把这些数字化的文字给转换出来(导出)便于日后翻译,在翻译完后还要利用程序把翻译好的内容导入游戏程序中。文本脚本的导入导出实现的手段相对比较多,如多你稍微有一点编程能力的话还是最好自己编程,毕竟每个游戏都有每个游戏的特殊性(见得多了自然就会感觉到的)。如果实在没有这个能力只有借助现成的工具了,比较常用的就是《Script Extractor》和《Script Insertor》,两者是双胞胎前者导出后者导入,无论你采用自编软件还是使用《SEX/SIN》都需要编写一个码表文件。前面说过编码的集合就是码表,导入导出工具程序根据码表说明的对应关系来转换数字和字符的,码表就如同一本数/符字典。
码表编写很简单,Windows的记事本程序就可以编写了,格式上不同的工具会有不同的要求,如果是自己编写的处理程序格式可以自己定编写格式,不过最好还是采用目前通用的书写格式比较好。通用格式为:
(字符编码1)=(字符1)
(字符编码2)=(字符2)
(字符编码3)=(字符3)
……
编写的时候一般是按照编码从小到大的顺序编写的。以下是我书写的《光明之魂2》码表的部分内容:

《光明之魂2》的原始字库有七八百个字,一行一行地写也确实费事,书写的时候注意积累经验。小技巧:先用EXCEL(不会没用过吧?)创建形如这样的表格:
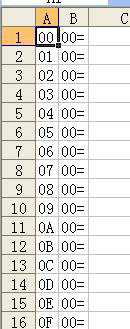
然后往下使用粘贴复制大法,一分钟就能搞定所有的编码了。接下来再对照《字模精灵组合器》里显示的字模一个字一个字地输入C列(老实点吧,这里就别想着用程序帮你写了。电脑把字库当图片了不会认识的。OCR可是世界难题哟,如果你真的写出这段程序的话就平步青云了,呵呵!!)。《字模精灵组合器》是设计成16*16字的显示模式并伴有显示字符位置的功能,每写一大段就对照一下位置,刚好可以避免遗漏掉字符(错位了可不得了呀,导出的文本会大变样)。等所有的字符都写完后就把全部内容粘贴到记事本中,最后替换掉制表位空白(TAB)就可以了。写完后一定要检查最后一个编码,代入游戏中看是否正确。检查完毕后就可以保存下来了,tbl是码表的公认扩展名,其实个人认为txt也未尝不可,两者的实际内容是一样的,而且这样更便于查看编辑。
在《光明之魂2》的文本脚本之中你还会发现一些形如“FFF?”这样的编码,而这些编码在游戏中并没有具体字符与之对应,而是出现的主角名字、字符显示速度减慢、换行、分段等等的控制功能,这样的编码称作控制符。写码表前不仅要摸清楚每个字符的编码而且还要弄清楚游戏中有多少控制符,每个控制符的具体功能是什么。我所研究出来的是:F5FF=主角名、F6FF=主角名、F7FF=数值、F8FF=恢复速度、FAFF=慢速、FCFF=主角名3、FFFF=换行、FEFF=块结束、FDFF=段结束等等。至于这些控制符该不该往码表文件里面写就要看程序是怎么设计的了,绝大多数程序都是要求从外部键入换行分段这些关键控制符的,其他只影响文本显示的控制符一般就写入码表,同文本一并导出。对于像减慢速度、变换字体颜色这样的控制符无法在导出的纯文本文件中体现,就可以将它们用特定的符号表示,自己记清楚哪种符号表示什么。还有一些不知道功能的控制符也可以用某个特别符号来表示,如果这样的控制符很多的话道出文本钟就会相应地出现过多的符号不便于浏览翻译,这时可以让程序把这些未知的控制符的值输出到导出文本中就可以的。不过要注意,因为这些文本在翻译后还要再次导入游戏中,同样需要靠工具程序完成,因此在设计导出程序的时候尽量考虑一下导出时候的处理,例如对未知控制符的值在导出的时候就可以加上“[ ]”符号括起来等等,导入时候程序判断到有这个符号便照中间的内容直接写入游戏中,而不用转换。办法都是自己想、自己定,初次接触难免有考虑不周的地方。
码表做好后接下来就该搞清楚游戏ROM中哪些才是脚本内容?我们该导出哪些?一般地说在游戏文件中文本脚本都是一句接一句地放在一起的,构成脚本区。可能所有的文本脚本都放在一起也可能脚本会分割成几个大的段分别来放置,前者为数更多。只要我们找到了一段脚本区的最开始就可以顺次导出了,所以找出脚本头是最关键的。至于查找实际上是不用什么特殊工具来完成的,在这里靠工具不如靠自己肉眼观察。这次我们从《光明之魂2》第一关的第一句开始找起。
到了这里大家已经整理好了码表,所以就可以把这句话直接翻译成编码后用《UE》查找就可以了,完全不用上一节介绍的方法,那样操作太复杂了。大家头脑一定要清晰,我们所做的每一步都是由针对性的。两分钟搞定,查找到0x368578,这就是句子的开始。根据一系列的试验我们发现一句话的构成:开头4位“00 00 01 00”为脚本句子的开头(在与NPC对话的时候这里标示说话人头像的代码),然后紧接着就是句子主体,其中还包含一个换行符“FFFF”(因为游戏文本区显示14*2个字符。由于该游戏并没有自动处理换行的程序,换行是靠控制符实现的),“FDFF”是一段的结尾符。等我们总结出脚本的特征后就在附近浏览看看哪些地方还有这些特征,有这个特征的多半就是文本。经过一阵的观察发现从0x368574以后的很大一块区域具有该特征并具有连续性,而这之前的区域没有这个特征。

基本上就可以认为0x368574就是脚本的开头了,起码应该是这一块脚本的开头。至于还有没有其他的先可以不考虑,等到文本导出后再说。至于脚本的结尾到不用太在意去找了,导出的时候多导出点超出也没什么关系,大不了把后边的多余部分删除掉就完事了。
文本脚本导入导出工具强烈建议有能力者自行编写!这可以让你更加深入地理解脚本的原理。本人汉化《光明之魂2》采用了PGCG汉化小组自行设计的一套导入导出工具,经过以上分析并编程得到导出文本(片断演示):
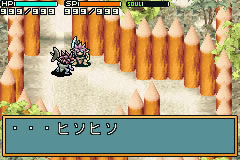
<368578>···ヒソヒソ
<36858E>···え?そうなんですか?
<3685B0>シッ!今···物音がしたぞ
<3685D2>あ···今の···私のおなかの音です……
大体上介绍一下《Script Extractor》。《Script Extractor》是使用得比较多的导出工具,该工具是以字节为单位导出数据并转化为文本的,所有控制符要求写入码表中。“line: xx”表示行结束;“msg: xx”表示块结束;“sect: xx”表示段结束;“prog cont char: xx=...”表示控制符,其他功能可以查看软件的README,有详细说明。
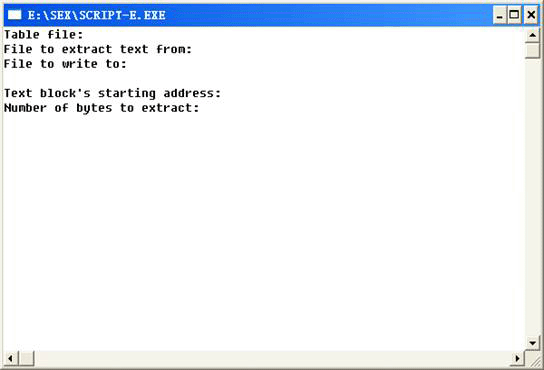
从上到下依次输入的是码表文件名、ROM文件名、导出文本文件名、导出开始地址、导出文本量(字节)。该工具有个最大的弊端就是导出的文本段没有注明脚本的地址,这会给导入制造很大的麻烦,好在程序包里面附带了C++源程序可以修改,不过不懂C++还是慎用该工具。《Script Insertor》主要功能是导入,操作方法和《SEX》差不太多,具体运用还是查看说明文档。除此之外还有一款国产的文本工具《菜鸟》,是由汉化者“菜鸟小生”编写的,功能设计上比较全也比较杂,初学者不太容易掌握。这个工具可以在《游戏汉化联盟》网站上下载。
在这节的最后我再谈谈计算机编码的问题。虽然之前我说过计算机编码和游戏编码一点联系也没有,但GBA游戏最初也是在电脑上编写的,某些程序员为了编写效率降低成本也可以说是懒惰、偷工减料,部分甚至全部采用了计算机编码,如果是这样的话倒是给我们汉化时编写码表带来了不少方便。字库编码是字库组织的依据,不同国家和地区有不同的编码标准,和中文字库有关的常见编码有:单字节编码、GB2312-80、GB12345-90、GBK、Unicode编码、ISO10646 / Unicode字符集、GB18030-2000、BIG5编码、方正748编码,下面简要介绍几个比较常用的:
“MS Windows:Windows Latin 1(ANSI)”这是Windows操作系统最基本的默认编码,在记事本的另存为对话框里可以清楚地看到这个编码。
“GB2312-80” 全称是GB2312-80《信息交换用汉字编码字符集 基本集》,1980年由中国颁布,是中文信息处理的国家标准,在中国大陆地区及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码(时不时感到自豪呢?)。在中文Windows3.2和苹果OS中就是以GB2312为基本汉字编码,Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。该编码共收录6763个简体汉字、682个符号,其中一级汉字3755个,以拼音排序,二级汉字3008个,以偏旁排序。该标准的制定和应用为规范、推动中文信息化进程起了很大作用。互联网上的大多数简体中文网站都是采用这个编码的,在网页内查看一下编码就知道了。在1990年国家还颁布了“GB12345-90”字符集,主要添加了非常用字和繁体字部分,以适用于古籍等的编定。此外中文字库还有“GBK”、“BIG5”等等,后者在中国香港澳门以及中国台湾得到广泛使用(知道为什么以前玩台湾游戏会出现乱码了吧?需要切换一下编码的)。还有一种特殊的编码“Universal Multiple Octet Coded Character Set(Unicode)”,这是一种包含有中日韩等多国文字的编码集,是由美国人颁布的(吃饱了就该看好世贸)。
“Shift-JIS”、“EUC-JIS”等等这些都是鬼子们国内使用编码,在游戏机游戏中前者更为常见,虽然游戏本身用不到这么多字符但不用自己去整理文字了,省事啊。
以上这些编码的详细标准以及码表很为庞大,这里考虑篇幅不详细介绍,有兴趣可以查看文字处理方面的网站,比如“方正字处理”等等,这是一门学问别小看了。
小结:这一节介绍了文本脚本的导出,理论并不深入但过程比较繁琐,大家要理清头绪。在编写字库的时候又有几点:日文汉字输入可以安装一个日文输入法,以前95下玩港台游戏所使用的《南极星》就不错,Windows自带的字符映射表也可以,里面有所有日文字符的(还有尼加拉瓜文字?厉害)。书写编码的时候也要注意到导出工具的特征,是不是需要高低反等等,就拿上面我编写的那个《光2》码表来说,由于导出工具是以字节为单位读取数据的(编写程序上要相对简单些吧),所以就需要高低反;你自己编写工具是双字节的就不需要反了。书写字符的时候尽量采用ANSI或者GBK,对于游戏中的特殊符号找不到的可以使用近似符号代替,反正我们又不去翻译符号,不过还得记清楚符号之间的对应关系。如果汉化的游戏文本很大,那千万不要使用《SEX》,因为没有标出文段地址,而大多数情况下翻译后的中文句子字符数量远远小于日文句子,如果没有地址标示在写入的时候只能顺序写入,于是就会发生脚本前移的问题。上面的《光2》文本导出演示可以清楚地看到每句前都有地址标示。自己在编写工具的时候也一定要记得让程序标出地址,切记!!。还有就是本节之所以不以上一节的那句“请选择……”开始查找是因为对话文本的情况最为复杂,控制符也最多,我们在导出文本之前一定要整理出所有的控制符一个都不能漏掉的。还有一个原因就是游戏的文本脚本一般都是按照出场的先后顺序写进游戏内容中的,从最开头的内容找起这样更容易发现脚本头部。不知道大家玩了PGCG汉化的《光明之魂2》中文版没有?游戏中的文字显示的时候偶尔花屏甚至造成死机,这全都是因为我当初在书写码表的时候没有分析完整,把其中一个为“FFFE”的控制符给漏掉了,到后来导入的时候恍然大悟,灰心丧气差点没气死,最后还是手工一句一句导入的,不得已采用了一些非常手段,最后还是造成了游戏运行的不稳定,而VBA模拟器对这个游戏本身兼容性也有一点问题(绝非推卸,那个飞天的恶魔天使赖着不下来和中文版没有关系)才使游戏出现这个BUG。以身说法是为了让大家知道不在意细节会酿成怎样的后果?大家一定要细心!
九 文字篇(四)
文本到底有没有导出完?这个问题基本上就是凭经验了,先大体上玩玩游戏,看看游戏中那些地方会出现文本句子。一般来说游戏制作者会把游戏中剧情对话做成一个脚本块;NPC对话做成一块;道具名称做成一块;菜单指令介绍等一块;相关介绍一块……。块与块一般情况下还是分开放置的,所以有时候就得分开查找。例如在《光明之魂2》中文本文字按照出现地点可以分为剧情对话、NPC对话、道具名称、介绍、指令和图鉴部分。运气特别好,虽然这几部分内容是独立的,但都被放在了一起(《光2》程序员BT啊,怪物图鉴部分竟然要做两套内容完全一样的文本脚本,分别对应一周目和二周目。当初我也没发觉这个问题,这也造成当时有很多人说图鉴部分没有汉化的原因)。
文本脚本也是非常之灵活多变的,基本上每启动一个游戏汉化项目就得重新做一次导入导出工具(也不是全部重新来,基本上修改个别参数、某个结构就可以了)。文本脚本在总体结构上可以分为三种类型:顺序结构、指针表结构、跳跃结构。
顺序结构:

这种结构最为常见也最简单,每一个文段都是紧挨着的,段与段之间有一个承接符来表示前一段的结束和后一段的开始。句子有伸长缩短改改这个控制符的位置就可以了,很简单的。这种结构在《光明之魂2》中相当的多,而承接控制符就是“FFFE”了,大家自己可以试试!
指针表结构:
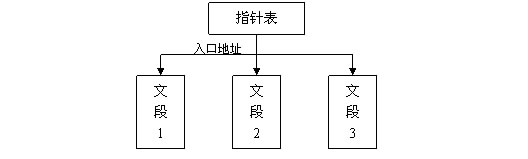
接触过编程的人一定会知道指针是什么意思吧,指针就是指向目标的地址,多个指针构成的向量表就是指针表(实在搞不懂就把它想象成码表)。在指针表内指针按一定次序依次排列,程序就是靠他引导定位文本脚本的,有的游戏一句话就有一个指针,但有的是一个场景对话才有一个指针。通过对指针的修改就能达到移动文段的目的,比如当“文段1”修改后长度如果出现增加,为了不影响句子的正确显示,这时我们就得把“文段2”往后(高地址方向)移动,并修改对应的指针让它再次指向“文段2”的头部。还是《光2》上面那句话为例子,该句从0x368574开始到0x368589结束。取得句首地址0x368574把它转换为GBA内存地址0x08368574(不同的游戏机由于硬件基础不同,转换的方法也不同。对于GBA来说游戏机把卡带内容影射到内存中从0x08000000到0x09FFFFFF的一块区域内进行寻址操作的,所以直接在地址前加上08000000就可以了)。高低反得到“74853608”,用《UE》搜索找到唯一一个地址:

观察一下不难发现该段很有规律。的确,你所看到的就是指针表,一个个指针顺次排列。把我们搜索到的指针改为下一句话的起始地址0x36858A,在游戏中原先的那句话变成了你所修改指针的指向的这一句了。现在你该体会到指针表的含义了吧。继续对指针表研究,不难发现其规律——《光明之魂2》是每一小段剧情一个对话指针的。
跳跃结构:

这种结构最为麻烦,规律最难把握。文段与文段之间夹杂很多“垃圾”,比如程序指令等等,少则几个字节,多的可能几百个字节也不为过,有时候移动一下位置都会造成问题,对于这种情形只能祈祷游戏中少出现些了。处理这种结构的时候一定要小心中间的那些“垃圾”千万别真的把它们扔掉了!!,导入导出程序也要考虑怎样合理处理这些“垃圾”,必要时候手工操作也是难免的嘛。《光明之魂2》中道具名称就属于这类情况,经过反复对照试验发现同一类型的道具名称地址的差是一个定值,相对来说降低了不少难度。
由此可见三种结构在《光明之魂2》中都有所出现,在你今后汉化游戏的时候肯定会遇到这样那样的特殊结构,但无论哪种结构都不外乎以上三种的有机组合。大家一定不要吝惜花在结构分析上的时间,否则“一失足成千古恨”。
文本导出完毕后大体上检查一遍,如果没什么问题的话就可以进行翻译了。翻译可以交给懂外语的朋友或者网友等等的,当然如果你自己会的话更好。翻译的时候仍然要注意书写的格式,为了避免导入时候不必要的麻烦一定要采用统一的格式。一般地,翻译内容都是跟在原文以后的。以下是《光明之魂2》的翻译片断,仅供参考:
<368578>
···ヒソヒソ
---
···咕~
<36858E>
···え?そうなんですか?
---
···嗯?有动静?
<3685B0>
シッ!
今···物音がしたぞ
---
嘘!
刚才···有什么声响
<3685D2>
あ···今の···
私のおなかの音です
---
啊···刚才是···
我肚子发出的声音
原文和译文之间加入的“---”只是为了方便导入程序识别而已。如果你要使用《SIN》来导入的话还需阅读说明文本并按照它的版式要求书写译文。等到所有文本都翻译完毕后还有一个非常必要的环节——文饰。翻译的时候基本上都是以文字字面意思来进行的,单独一句是没有什么问题,但拿到游戏中连续起来问题就大了。所以在完成翻译后要整理译文,让对话通顺流畅符合中文习惯等等,如果再追求一点可以让译文突出说话角色的性格特征等等,如果方便可以请教有文学功底的朋友来进行剧情润色。润色完毕后还要对整篇文章逐句安全检查。看看每行字符是否超出范围;控制符书写是否正确、是否配对完整(比如文字变色、慢速等等有起始符还有终止符);标点符号是否统一,特别注意半角符号和全角符号,在电脑看来“,”和“,”是不同的符号,除非你在做码表的时候都有定义……。文本检查相当重要马虎不得!!!
小结:本节内容不多、分量十足,文本导出的落脚点不是仅仅为了翻译,而是要为翻译后的导入过程。导出是否完善直接影响导入的成功与否,在设计辅助工具的时候要想着怎样排版既方便翻译时正确阅读理解文字内容,还要考虑这样排版日后是否能使工具正确识别转换其中的文字信息并写入游戏文件中正确的位置。特别是有跳跃脚本(也称“飘浮脚本”)的游戏怎样避免改动文段间的指令部分是设计的关键。建议在完全把握脚本后先写导入工具然后再写导出工具,导出后先利用一小段文本测试导入工具,确认没有任何问题后再进行翻译。翻译的时候考虑到别人可能对汉化并不太了解,所以一定要给对方说清楚具体操作。最后需要说一点:导出文本的时候如果脚本有包含说话人的信息也要一并导出来,这样会提高翻译时的效率和准确率。对于《光明之魂2》,前面说过在每一句开头的4个字节就是说话人,这些信息也最好导出,哪怕是导出个说话人的代码也可以。而当初我并没有在意这一点,所以整个汉化消耗的时间大部分都浪费在了翻译上,没有说话人的翻译是很伤脑筋的。
十 文字篇(五)
翻译完了也整理修改完了接下来就可以考虑把译文中出现的所有中文汉字的字模导入游戏文件里面,如果以前的日文字模都不会再出现的话直接覆盖掉原字模就可以了。多数时候可能还是会保留英文字符、符号、日文平假名、片假名而仅仅是替换日文汉字部分。由于中文汉字数量庞大,一个剧情比较简单的GBA角色扮演游戏少的都有八九百个中文字符,而原始的字库空间有限无法容纳下那么多中文汉字。比如《光明之魂2》原始字库有700个左右,去除英文大小写字母和符号就更少了。对于这种情况我们就必须对原来的字库扩容。
一般的情况下,每个游戏之中总会有部分空白区域,换句话说文件的内容并不一定连续,我们可以适当地利用这些空白,如果这些空白仍然不够使用就可以把新字库生成到原来文件的末尾区域以达到扩容的目的。新字库扩容后还需要修改字库地址的计算公式,很多时候文件中都有一个基址指针,适当地修改就可以达到目的,不过寻找起来有点麻烦,倘若运气好就是一个绝对地址,就像文本脚本的指针一样,这样寻找起来就比较简单了。还有两点需要注意:即便是在游戏末尾添加的字库也不能删除原字库,如果删除了会使字库后边的程序迁移而失去原有功能,指针地址会指向错误的地方,所以只能替换,绝不能进行添加删除等会造成位置移动的操作,这也是整个汉化过程自始至终都要注意的。有些游戏的容量必须使用标准的容量,特别是任天堂的游戏。1Mb 2Mb 4Mb 8Mb 16Mb 32Mb等等,这些是任天堂定的标准容量,如果字库扩容后超出了上一级的标准容量就必须满足次级的容量。比如说一个8Mb的游戏扩容后可能到了10Mb,我们就需要继续在文件末尾添加“垃圾”一直到16Mb为止,某些游戏在文件的头部还记录了整个文件的校验信息甚至文件的容量大小,扩容后这些地方也需要改,比如SFC。好在对于GBA来说并没有这么多的关联地方。
新字库的生成最好使用工具来完成,除非你觉得有那份闲情逸志喜欢手工描绘。生成前需要把翻译文本中所有用到的汉字都统计出来(可以使用《Counter》),然后再生成,这样做既避免了字模的重复又不会产生垃圾字模。
字模生成后就可以制作新码表了,其实这个步骤可以在生成新字库的时候一起完成了,每添加一个字模就产生一个对应码,依次进行下去。这里的字符编码并不是由你自己定义,而是由原编码来决定的。比如在原码表中“0001=A”,在你把“A”的字模替换成了“啊”以后对应关系就是“0001=啊”,字符编码是用作位置计算的,特别是在扩容字库后一定要认清楚对应的位置关系。整个字库都导入完毕后可以使用《TLP》这些工具再次查看一下字库是否已经按照要求排列好了。
以上都准备完毕并确认以后就可以导入文本了,这个过程基本上和导出相逆,同样建议自己编写工具完成,《SIN》实在不怎么样。导入的时候注意整体的统一,如果个别句子移动了位置还要考虑是不是有指针等等,每个细节都需要去考虑,考虑得越多出现问题的机率越小。
导入完成后基本上游戏的文字汉化就结束了,最后就是找几个爱玩游戏的朋友适当测试一下,看看有没有什么BUG的。对于GBA游戏来说最好是VBA模拟器上和GBA游戏机上都进行测试。虽然说VBA模拟器游戏兼容性很高,但模拟器绝不能简单地认为是电脑上的游戏机,等你对模拟器实现原理有一定了解后就知道为什么要这样说了。换句话说就是这个世界上没有100%兼容的游戏模拟器,除非游戏机也使用Inter的80x86CPU。在发现问题后记录下详细的情况,以便后期进行修改并再次测试。模拟器上的测试可以适当使用记忆功能来进行测试,再次提醒大家,慎用模拟器的即时记忆(VBA的.sgm),尽量使用游戏自己的记忆功能(VBA的.sav)。


小结:多数时候,一个游戏并不是只有一个字库系统,有两个三个是很正常的事情,各个字库分工不同,有些是用来显示正文的;有些是用来显示道具名的;有些是用来显示人名的等等。比如《光2》就有两个字库系统:游戏开始输入玩家姓名的时候使用的8*8的小规模的字库,而游戏中的文字使用了16*16的主要字库。基本上每个字库都是独立存在的互不影响,这时每个字库就可以单独研究并进行修改,但有时候也是有联系的,比如《光2》虽然有两个字库,但这两个字库是重叠的,8*8的取名字库的码表和16*16字库的开头部分是一致的,因此16*16这个字库的最开始的百多个字符将会出现在取名系统里,为了符合取名的意义,所以也要适当地排列一下字模的前后顺序。又如《SD高达》里面12*12的字模和8*12的字模就是完全独立的,互不影响。
到这里本教程的文字汉化的基本原理介绍就结束了,教程的介绍相对浅显,还有很多很多问题无法通过几万的汉字就能说清楚的,多数时候遇到问题都需要你自己去解决。教程介绍的情况都是最基本的,但实际情况下很多时候都会存在压缩格式甚至OBJ对象这些比较难以解决的问题。要想修改的话就必须先进行解压缩(可别以为需要Winzip WinRAR什么的),因此就必须得研究压缩的算法等等,这些都是需要进行ASM跟踪破解游戏程序。只有ASM才是破解游戏最万能的方法,下一节适当地为大家介绍一下ASM,不过你得对汇编有一定了解才行。
十一 ASM篇
并非需要很多的计算机知识才能够进行程序跟踪,当然要想便捷有效的跟踪程序的确需要扎实的汇编语言基础。许多朋友都是出于个人爱好才接触汉化的,如果一开始进行跟踪就学习大量的硬件知识和汇编知识一定会感觉吃力而对自己丧失信心。其实学习ASM HACK完全可以遵循循序渐进的原则,先使用最简单但比较费力的方法,通过对程序认识的深入再不断改进自己的跟踪手段来提高效率。在这篇文章中我将讲解如何使用比较原始的方法来捕获游戏图片在ROM中的位置,这只是跟踪的第一步,如果想要捕获显示程序或解压程序就需要了解更多的知识才能实现,但这是后话了,让我们先从最简单的开始。
工具软件:
BATGBA模拟器(一款免费的GBA模拟器,带基本的DEBUG功能。对于初学者不推荐使用NO$GBA) UltraEdit(全球最著名的文本编辑器,功能强大,中文界面)
技术手册:
ARM指令集手册(ARM是GBA使用的处理器芯片,学习汇编的必备工具书)
几本计算机基础书籍(良好的计算机基础是你进行汉化的必要条件)
其他:
很多很多的耐心和一点点运气
在我们开始跟踪之前有必要了解一下GBA的芯片和模拟器的用法,大家开始的时候不用彻底学习这些知识,只要知道用法就可以。GBA使用的是ARM7TDMI处理器芯片,它和我们常见的INTER或AMD芯片有很大区别,不要把二者混为一谈。ARM使用RISC(精简指令集)架构 32位 16.78MHz。我们跟踪主要需要了解的是它的寄存器结构和汇编代码。ARM 处理器有二十七个寄存器,其中一些是在一定条件下使用的,所以一次只能使用十六个。
寄存器 0 到寄存器 7 是通用寄存器并可以用做任何目的。
寄存器 8 到 12 也是通用寄存器,但是在切换到 FIQ 模式的时候,使用它们的影子(shadow)寄存器。
寄存器 13 典型的用做 OS 栈指针,但也可被用做一个通用寄存器。
寄存器 14 专职持有返回点的地址以便于写子例程。
寄存器 15 是程序计数器。它除了持有指示程序当前使用的地址的二十六位数之外,还持有处理器的状态。
寄存器在程序中的表示符号是R0-R15,大家先不要深究这些寄存器的功能和区别,只要知道这些寄存器的名称就可以,然后我们讲关键的地方。
GBA和电脑一样,在运行任何程序时都遵循一个过程,先从卡带(ROM)里将程序或文件读入内存,然后将内存中的程序或文件按一定顺序装载到寄存器中,再由寄存器与处理器交互处理,将处理结果返回内存中。正是因为我们可以通过模拟器观察这个过程,才有跟踪的实现。那么GBA是如何将文件从ROM中装载到内存的呢?GBA在运行的时候将内存划分成一个连续的区域。用地址表示就是00000000H-FFFFFFFFH其中00000000H-08000000H是实际意义上的内存空间,而08000000H以后的地址则是ROM的地址映射,也就是说08000000H就是实际ROM中的首地址00000000H。GBA通过这个映射地址来读取ROM中的文件,理解这个概念很重要,也就是说你在寄存器中观察到的以08XXXXXXH表示的地址即说明此刻程序正从ROM里读取相应的文件,可能是程序,图片,文本,字库。这些正是我们需要找到的东西。
如何才能截获这个地址呢?这就是模拟器的工作了,现在几乎所有的GBA模拟器都带有跟踪功能,允许你查看游戏运行过程中内存和寄存器里的内容,通过观察寄存器中的数值和内存中的程序,我们可以滴水不漏的获得游戏运行的全过程。以下让我们看看模拟器是如何跟踪游戏程序的。
打开BATGBA,看看DEBUG菜单下的内容,第一项是ENABLE,开始跟踪时可别忘选上它,否则跟踪无从谈起。第二项是UPDATE DIALOGS,这是自动刷新功能,当然跟踪时也要选上,否则你只能看到静止不动的程序。第三个选项就是我们的主角,观测功能菜单,在这个菜单中提供了10个不同的观测对象,我们主要用到的是最上面两个对象,CPU和DISASM。让我们选择这两个对象,这时候我们看见如下的两个窗口:
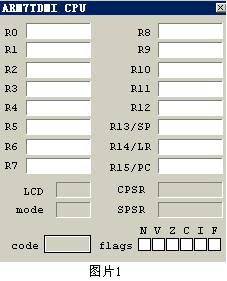
(图片1)ARM7TDMI CPU窗口,你一眼就可以认出来,这个窗口表示的就是我们上文提到的GBA使用的那15个寄存器R0-R15,没错。既然所有的程序都必须经由寄存器才能与处理器交互,那么我们要找的地址也不例外,那些08XXXXXXH表示的地址都会在这些寄存器中出现,你只要在跟踪过程中从这些寄存器窗口中抓到它就可以了。
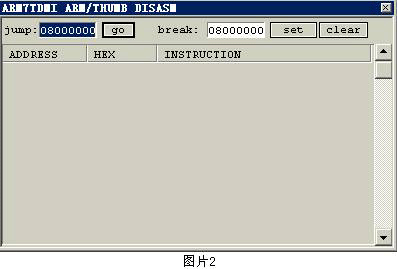
(图片2)ARM7TDMI ARM/THUMB DISASM窗口,就是将GBA内存中的数据反汇编成ARM汇编语言的窗口。通过这个窗口,我们可以以汇编语言的形式而不是二进制代码的形式来观察程序的运行过程,这大大方便了我们了解游戏是如何运行的。不论是字库显示程序,解压缩程序还是图片调用程序都需要在内存中运行,这些程序会被反编译成ARM的汇编指令在这个窗口显示,找到这些程序就是我们跟踪的目的。

下面我们以GBA游戏拿破伦传为例来看看怎样找到这个游戏中一个图片文件在ROM中的位置:
(图片3)是我们需要找到图片文件,思考这样一个问题,GBA是通过哪几个步骤来完成这个图片的显示的?首先,GBA先将图片文件从ROM中读入内存,然后调用图象解析程序来处理这个图片文件,最后输出到显示屏上显示。我们暂时不考虑它的解析和输出过程,只要抓到它读取图片文件时的过程就可以找到它读取ROM的位置。那么它从哪里开始这个过程的呢?让我们看看这幅图片显示前的状态。

(图片4)是游戏里的一个选择菜单,当我们选择指挥官设定选项时,游戏随即显示我们需要跟踪的那个图片,也就是说,从你按下按键开始到(图片3)开始显示的这个过程中即包含了游戏调用图片文件的过程,我们就从这里来寻找图片文件在ROM中的地址数据。
BATGBA提供了4种不同的跟踪模式,STEP INTO(F7),STEP OVER(F8),STEP LINE(F9),STEP FRAME(F10)这4种模式对应不同的程序运行流程,大家先不要深究它们,先这样理解,GBA在执行程序时是一条语句一条语句执行的,这4种模式对应不同的中断模式,打个比方说STEP FRAME(F10)是程序执行100条停止一次,STEP LINE(F9)是执行10条停止一次,而STEP OVER(F8)和STEP INTO(F7)则是每执行一条就停止一次。当然还有一个中断程序的方法,就是按(F4)键。你可以在游戏运行中的任何时候中断游戏。有了这5种中断模式我们就可以在游戏执行时在需要的地方暂停游戏来观察此时GBA寄存器和内存中的东东,也许你要找的图片地址就在其中。
上文我们已经圈定了我们跟踪的范围,从你按下按键开始到(图片3)开始显示,这个过程只有短短的几秒钟,打开模拟器载入游戏,然后进入(图片4)的菜单。这时打开ARM7TDMI CPU窗口和ARM7TDMI ARM/THUMB DISASM窗口,你可以看到此刻寄存器和内存中的全部内容,但是好象没找到象08XXXXXXH这样的数据啊?别着急,在(图片4)的菜单中选择指挥官设定选项,在你按下按键的同时立即按(F4)键,这时游戏停止了,我们的跟踪旅程也就从此开始,上文我们讲到的4种中断模式中的STEP OVER(F8)和STEP INTO(F7)是单步跟踪模式,我们随便选一种,比如STEP INTO(F7),在你再次按下(F4)的同时按下(F7)键。好,我们现在切换到单步跟踪模式了。这时你仔细观察ARM7TDMI ARM/THUMB DISASM窗口,每当我们按一次(F7),窗口里的指针就向下移动一格,这表明游戏程序已经执行了一步。看看ARM7TDMI CPU窗口,寄存器R0-R15里的数值也变化了。可是还是没看见有08打头的数据,慢慢来,继续按(F7),观察ARM7TDMI CPU窗口里寄存器里的数值,我保证你一定会看到以08开头的数据,记下你见到的所有08XXXXXX样子的数据,直到模拟器窗口显示出(图片3)为止。这时你也许已经记下了许多以08开头的数据,这里面肯定包括(图片3)的地址,但哪个才是真的呢?简单,使用UltraEdit打开游戏的ROM文件,我们前面说过了,GBA把ROM里的地址都映射到08000000H之后,那么将你找到的数据转化成ROM里的地址的方法就是将开头的08变成00,比如你找到一个08123456的数据,那么它在ROM中表示的地址就是00123456H。将你记下的数据都按这种方法转换成ROM中的地址,然后在UltraEdit找到对应的地址下随便修改几个字节,保存。再用模拟器打开修改后的ROM。看看(图片3)是不是变样了?没有,再换下一个地址试试,直到找到一个地址[我可以告诉你这个地址是:00759E37H在UltraEdit修改后(图片3)变样了,那么恭喜你,你已经找到你需要的东西了。
说到这里,你已经学会了使用最简单的方法跟踪了。但如果你真的按我上面说的一步一步跟踪程序的话,你一定会累死!别小看这短短几秒,其实程序已经执行了成千上万步了。如果一步一步跟踪的话,你一整天也跟不完。先别抱怨,谁让我们是菜鸟呢。便捷的方法当然有,但在你不了解跟踪原理,ARM汇编语言的情况下,这是唯一可行的办法,下面我们就来看看有没有更好的方法来提高效率。不过前提是你必须理解以上所说的内容,会使用单步跟踪来跟踪程序,否则提高无从谈起。
如果你懒的理会那些繁琐复杂的汇编语言,其实可以利用模拟器提供的功能来缩短跟踪范围。记得我们提到的那4个中断模式吗?我们只使用了两个,不是还有两个吗?STEP FRAME(F10)一次中断执行的语句最多。如果用它来跟踪以上过程的话,只需要按几次就可以跟完,但是你很可能会遗漏掉程序读取ROM的过程,毕竟STEP FRAME(F10)中断时的位置不可能正好就在程序读取ROM时。让我们将这几种中断模式组合起来。STEP FRAME(F10)既然一次执行语句最多,让我们先用它来进行一次粗跟踪,假设从你按下按键开始到(图片3)开始显示这个过程一共执行了一万条语句,使用STEP FRAME(F10)跟踪,我们一共执行了10次中断,记下每次中断时寄存器的状态。这样我们就把一万条语句分割成10等份,假设我们估计调用ROM的程序在第9到第10状态之间,先用STEP FRAME(F10)跟踪到第9个状态,然后用STEP LINE(F9)来跟踪。因为STEP LINE(F9)一次执行的语句比STEP FRAME(F10)要少,所以它能跟踪到这两个状态之间的程序。如果使用STEP LINE(F9)还是没找到,就用STEP LINE(F9)将这两个状态再分割成更细的状态,使用单步跟踪来查找。如此我们等于将程序化整为零,如果运气好的话,我们根本不需要从头到尾全部跟踪就可以找到我们需要的图片地址。
可是上述方法还是很笨,而且运气的成分太多。有没有更科学更有效的方法呢?有,当然有,这就是断点设置跟踪。它是目前最有效最科学的跟踪方法。不过要学习这个方法不了解程序和汇编是很难使用好的。让我们先了解一下程序的运行模式。不论是什么游戏程序都具有这样一种特征,假设我们把一个游戏程序看做一个完整的大程序,那么这个大程序就是由若干个功能相对独立的小程序组成的。他们可能是游戏初始化,图象显示,字库调用,文本调用,声音播放等等不同的功能,我们称这些具有相对独立功能的小程序为子程序。一个游戏程序就是由这一个一个子程序相互嵌套组成的。也就是说我们要找的图片调用过程也是子程序的一种,还有字库显示程序,解压缩程序都可以称为子程序。每条子程序都是由数量不等的汇编语句构成的。倘若我们能以子程序为单位而不是以单条语句为单位来进行跟踪的话不仅能大大提高效率,同时还能完整的捕获程序的代码,避免了盲目性。那么这些子程序在游戏中使用什么形式表示的呢?让我们以LZ77解压缩程序为例来看看子程序的模式。
00000DB4 LDR r2,[r0],#0x4
00000DB8 MOV r2, r2,LSR #0x8
00000DBC MVN r9,#0x0
00000DC0 MOV r10,#0x1
00000DC4 MOV r6,#0x7
00000DC8 LDRB r3,[r0],#0x1
00000DCC LDRB r8,[r0],#0x1
00000DD0 TST r10,r3,LSR r6
00000DD4 BEQ 0xE08
00000DD8 MOV r5,r8,LSR #0x4
00000DDC ADD r5,r5,#0x2
00000DE0 SUB r2,r2,r5
00000DE4 AND r8,r8,#0xF
00000DE8 LDRB r4,[r0],#0x1
00000DEC ORR r4,r4,r8,LSL #0x8
00000DF0 ADD r4,r4,#0x1
00000DF4 LDRB r8,[r1,-r4]
00000DF8 STRB r8,[r1],#0x1
00000DFC SUBS r5,r5,#0x1
00000E00 BPL 0xDF4
00000E04 B 0xE18
00000E08 TST r1,#0x1
00000E0C LDRNEB r7,[r1,r9]
00000E10 ORRNE r8,r7,r8,LSL #0x8
00000E14 STRH r8,[r1],#0x1
00000E18 SUBS r2,r2,#0x1
00000E1C BMI 0xE2C
00000E20 SUBS r6,r6,#0x1
00000E24 BPL 0xDCC
00000E28 B 0xDC4
这就是一段完整的子程序,它具有相对独立完整的功能。让我们实际跟踪一下看看它是如何运行的。找到一个使用LZ77压缩的游戏(如逆转裁判或铸剑物语)用模拟器打开,这时请看ARM7TDMI ARM/THUMB DISASM窗口右上方,是不是有一个BREAK文本框?那就是我们设置断点的地方,先按(F4)键暂停游戏,在这个文本框里输入00000DB4,点击SET按键。好,我们已经设置好一个断点了。再按(F4)键运行游戏,不久游戏就停止在00000DB4处了。然后我们使用(F7)键单步跟踪一下,你会发现窗口里的指针总是在00000DB4-00000E28之间来回循环跳转。这时让我们使用(F4)键中断试试。哈,每按一次,程序就中断到我们设的断点位置,同时观察ARM7TDMI CPU窗口中寄存器的变化你会发现子程序进行了一次循环。这样我们一次中断跟踪就是以一次子程序循环为单位,再也不用逐条语句的看了。象这样的子程序在游戏中随处可见。随便你找个什么游戏,使用单步跟踪观察一下就会发现,ARM7TDMI ARM/THUMB DISASM窗口中的指针总是在一个地址段中循环执行后再跳转到下一个地址段继续循环执行。这样一个连续的循环地址段所包含的语句段都是子程序。那么什么时候程序才能跳出一个循环到下一个循环呢?这就要求你能读懂子程序的跳转条件了。先别着急去读它,我们先总结一下设置断点的步骤,首先找到游戏程序中的一段子程序,然后在子程序开始的位置设置断点,断点的表示方式就是子程序在内存中的地址。
这就是设置断点的跟踪方法,在实际跟踪中我们往往需要综合我们上述讲到的所有方法来协调跟踪。首先圈定你的跟踪范围,在这个范围中使用单步跟踪或分割跟踪先找到一段子程序,在子程序的开始位置设置断点,转换成断点跟踪模式,努力读懂子程序的跳转条件,找到子程序跳转后的位置,再在这个子程序将要跳出循环时使用单步跟踪跟到下一个子程序,再设断点继续跟踪下一段子程序,如此下去,直到你找到需要的图片显示程序或字库显示程序为止。
断点跟踪是不是很奇妙?不过这时你也许会抱怨BATGBA模拟器了,它每次只能设一个断点,有时跳转条件没读懂还容易跟出界。没办法,剑术既然已经高超了,让我们换更好的剑使用。NO$GBA,这个模拟器可以一次设好几个断点,同时允许你自己设定程序运行多少步中断一次,不用担心跟出界了吧?还有CowBite,它允许你倒退跟踪几步来观察程序,这对于寻找子程序跳转位置太有用了,不过它对游戏的兼容性一般。
小结:ASM跟踪的基本方法我们就讲完了。(什么?这只是基本方法????)没错。真正跟踪的时候光靠这些是不够的,你如何圈定你的跟踪范围,如何判断你找到的地址和程序就是你需要的。这些就有赖于你对汉化其他知识的了解了,字库,文本,图片的结构,压缩算法等等知识。你对游戏汉化了解的越深,跟踪起来就越得心应手。大家也许奇怪我在文档中只字未提ARM汇编语言,原因是想讲清一门语言不是三言两语就能说清的。这需要你平时不断的积累,学习,多读多看程序。那本ARM指令集手册就是最好的教材。你不一定全读懂,能读懂40%再看子程序就容易多了。文中提到的所有技术手册和软件各汉化网站都有下载,还等什么?马上开始你的跟踪之路吧。
十二 压缩篇
本节介绍几个常见的压缩算法。
(一)字典算法
字典算法是最为简单的压缩算法之一。它是把文本中出现频率比较多的单词或词汇组合做成一个对应的字典列表,并用特殊代码来表示这个单词或词汇。例如:
有字典列表:
00=Chinese
01=People
02=China
源文本:I am a Chinese people,I am from China 压缩后的编码为:I am a 00 01,I am from 02。压缩编码后的长度显著缩小,这样的编码在SLG游戏等专有名词比较多的游戏中比较容易出现,比如《SD高达》。
(二)固定位长算法(Fixed Bit Length Packing)
这种算法是把文本用需要的最少的位来进行压缩编码。
比如八个十六进制数:1,2,3,4,5,6,7,8。转换为二进制为:00000001,00000010,00000011,00000100,00000101,00000110,00000111,00001000。每个数只用到了低4位,而高4位没有用到(全为0),因此对低4位进行压缩编码后得到:0001,0010,0011,0100,0101,0110,0111,1000。然后补充为字节得到:00010010,00110100,01010110,01111000。所以原来的八个十六进制数缩短了一半,得到4个十六进制数:12,34,56,78。
这也是比较常见的压缩算法之一。
(三)RLE算法
这种压缩编码是一种变长的编码,RLE根据文本不同的具体情况会有不同的压缩编码变体与之相适应,以产生更大的压缩比率。
变体1:重复次数+字符
文本字符串:A A A B B B C C C C D D D D,编码后得到:3 A 3 B 4 C 4 D。
变体2:特殊字符+重复次数+字符
文本字符串:A A A A A B C C C C B C C C,编码后得到:B B 5 A B B 4 C B B 3 C。编码串的最开始说明特殊字符B,以后B后面跟着的数字就表示出重复的次数。
变体3:把文本每个字节分组成块,每个字符最多重复 127 次。每个块以一个特殊字节开头。那个特殊字节的第 7 位如果被置位,那么剩下的7位数值就是后面的字符的重复次数。如果第 7 位没有被置位,那么剩下 7 位就是后面没有被压缩的字符的数量。例如:文本字符串:A A A A A B C D E F F F。编码后得到:85 A 4 B C D E 83 F(85H= 10000101B、4H= 00000100B、83H= 10000011B)
以上3种不RLE变体是最常用的几种,其他还有很多很多变体算法,这些算法在Winzip Winrar这些软件中也是经常用到的。
(四)LZ77算法
LZ77算法是由 Lempel-Ziv 在1977发明的,也是GBA内置的压缩算法。LZ77算法有许多派生算法(这里面包括 LZSS算法)。它们的算法原理上基本都相同,无论是哪种派生算法,LZ77算法总会包含一个动态窗口(Sliding Window)和一个预读缓冲器(Read Ahead Buffer)。动态窗口是个历史缓冲器,它被用来存放输入流的前n个字节的有关信息。一个动态窗口的数据范围可以从 0K 到 64K,而LZSS算法使用了一个4K的动态窗口。预读缓冲器是与动态窗口相对应的,它被用来存放输入流的前n个字节,预读缓冲器的大小通常在0 – 258 之间。这个算法就是基于这些建立的。用下n个字节填充预读缓存器(这里的n是预读缓存器的大小)。在动态窗口中寻找与预读缓冲器中的最匹配的数据,如果匹配的数据长度大于最小匹配长度 (通常取决于编码器,以及动态窗口的大小,比如一个4K的动态窗口,它的最小匹配长度就是2),那么就输出一对〈长度(length),距离(distance)〉数组。长度(length)是匹配的数据长度,而距离(distance)说明了在输入流中向后多少字节这个匹配数据可以被找到。
例如:(假设一个10个字节的动态窗口,以及一个5个字节的预读缓冲器)
文本:A A A A A A A A A A A B A B A A A A A
------------------------ ========
动态窗口 预读缓存器
动态窗口中包含10个A,这就是最后读取的10个字节。预读缓冲器包含了 B A B A A。编码的第一步就是寻找动态窗口与预读缓存器相似长度大于2的字节部分。在动态窗口中找不到B A B A A,所以B就被按照字面输出。然后动态窗口滑过1个字节,现在暂时输出了一个B。
第二步:A A A A A A A A A A A B A B A A A A A
------------------------- ========
动态窗口 预读缓存器
现在预读缓冲器包含A B A A A,然后再和动态窗口进行比较。这时,在动态窗口找到了相似长度为2的A B,因此一对〈长度,距离〉就被输出了。长度(length)是2并且向后距离也是2,所以输出为<2,2>,然后动态窗口滑过2个字节。现在已经输出了B<2,2>。
第三步:A A A A A A A A A A A B A B A A A A A
------------------------- ========
动态窗口 预读缓存器
继续上面的方法得到输出结果<5,8>。现在已经输出了B<2,2><5,8>。
最终的编码结果是:A A A A A A A A A A A B<2,2><5,8>。
但数组是无法直接用二进制来表示的,LZ77会把编码每八个数分成一组,每组前用一个前缀标示来说明这八个数的属性。比如数据流:A B A C A C B A C A按照LZ77的算法编码为:A B A C<2,2><4,5>,刚好八个数。按照LZ77的规则,用“0”表示原文输出,“1”表示数组输出。所以这段编码就表示为:00001111B(等于0FH),因此得到完整的压缩编码表示:F A B A C 2 2 4 5。虽然表面上只缩短了1个字节的空间,但当数据流很长的时候就会突出它的优势,这种算法在zip格式中是经常用到。
除此之外还有很多压缩算法,像霍夫曼编码(Huffman Encoding)等等。这些编码也是非常的著名而且压缩效率极高,不过这些编码的算法相对比较繁琐,规则也很复杂,由于篇幅就不逐一介绍了。如果大家对这方面感兴趣可以到网站相关网站查询资料。
小结:这一节介绍的几种算法在GBA上是比较容易遇到的典型算法,但绝不是说只有这几种,还是有很多时候都得自己ASM跟踪进行分析,这里介绍给大家希望能拓展大家的思维,方便进行程序分析,对于一切的问题ASM才是万能的。
十三 完结篇
要想成功汉化完一个游戏,首先是要对游戏机有一定的了解,这一节将给大家介绍一些关于GBA的机能资料,一定会对大家是很有帮组的。
一、GBA系统配置
CPU 32位RISC CPU(ARM7TDMI)/16.78MHz
兼容性 集成8位CISC CPU兼容于GBC,但是不能和GBA的CPU同时工作
内存 系统ROM 16K字节(对于GBC是2K)
工作RAM 32K字节+CPU外部256K字节(2倍周期)
VRAM 96K字节
OAM 64位×128
调色板RAM 16位×512(256色用于精灵,256色用于背景
卡带内存 最多32MB ROM或闪存+最多512Kbit SRAM或闪存
显示 240×160×RGB点、32,768色模拟显示、特效(旋转、缩放、α混合、浅入浅出和马赛克)、4图像系统模式(BG0-BG3)
操作 控制键(A、B、L、R、START、SELECT和方向键)
声音 4声道(相应于GBC的声道)+2个CPU直接声道(PCM格式)
通讯 串口通讯(8位/32位、UART、多玩家、多用途、JOY总线)
卡带 同DMG和GBC一样,GBA的卡带使用32针接口,GBA自动检测插入卡带的电压来判断卡带的类型并切换GBC或GBA模式。GB卡带、GB/GBC双重模式卡带、GBC专用卡带、GBA专用卡带都可以在GBA系统上使用。这也是GBA烧录卡为什么无法在烧录GB/GBC游戏后无法直接运行的道理,烧录卡电压仍然是GBA的低电压,GBA把他当作GBA游戏了。
二、GBA的内存
卡带内存
(分别设置各段空间的访问速度,用以优化对卡带ROM的存取。闪存用于保存数据) |
0E00FFFFH
0E000000H |
卡带RAM(0-512Kbit) |
镜像 |
0DFFFFFFH
0C000000H |
卡带ROM 等待状态2(32M) |
闪存(1Mbit) |
| ROM(255Mbit) |
0BFFFFFFH
0A000000H |
卡带ROM 等待状态1(32M) |
闪存(1Mbit) |
| ROM(255Mbit) |
09FFFFFFH
08000000H |
卡带ROM 等待状态0(32M) |
闪存(1Mbit) |
| ROM(255Mbit) |
| GBA机体内存 |
070003FFH
07000000H |
OAM(1K)精灵属性内存,储存精灵及其属性 |
|
06017FFFH
06000000H |
VRAM(96K)显存 |
050003FFH
50000000H |
调色板RAM(1K) |
04000300H
04000000H |
I/O寄存器 |
03007FFFH
03000000H |
CPU内部WRAM(32K)用于储存程序和数据 |
0203FFFFH
02000000H |
CPU外部WRAM(256K) |
00003FFFH
00000000H |
系统ROM(16K)包含多种系统调用 |
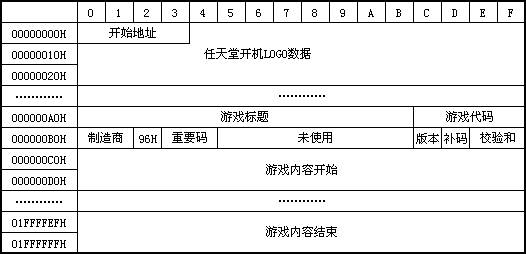
三、GBAROM数据
到此为止,本教程就结束了,但相信你对汉化的研究并不会因为教程的结束而结束的,汉化也是个永无休止的探索过程。这个教程只涉及了一些基础性的原理,很多具体问题都需要大家独立去解决,主要目的不仅教给大家一点理论知识,更是让大家学会如何去分析问题解决问题。教程中所涉及的专业词汇以及一些名词解释一方面为了方便大家理解、另一方面是由于汉化领域并没有标准统一过这些词汇的叫法以及解释,所以有一些并不一定十分准确。或许你在这里看到的和在另外一个地方看到的名词甚至解释都不大相同,这是很正常的希望大家能分辨清楚。同时也欢迎大家到“掌机之王论坛”、“PGCG论坛”与我们PGCG小组共同探讨汉化。最后祝愿大家都学有所成,祝愿大家早日汉化出自己喜欢的游戏,感受到游戏汉化出来的成就感,中文游戏玩起来的爽快感!!送给朋友,送给情人更是别有一分意义。